 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevealing Unfair Models by Mining Interpretable Evidence
Paper and Code
Jul 12, 2022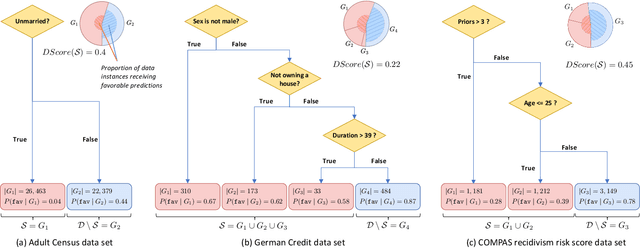
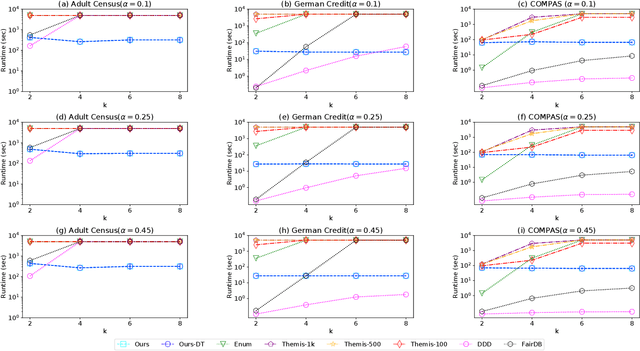
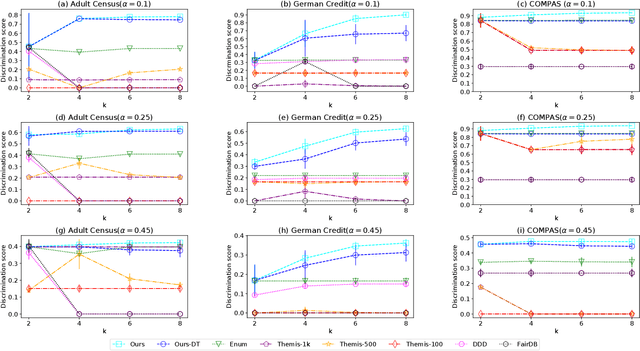
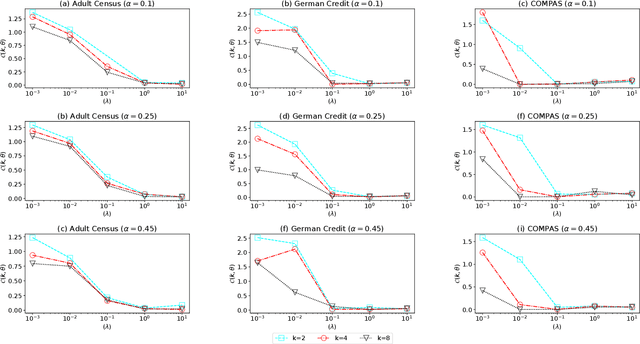
The popularity of machine learning has increased the risk of unfair models getting deployed in high-stake applications, such as justice system, drug/vaccination design, and medical diagnosis. Although there are effective methods to train fair models from scratch, how to automatically reveal and explain the unfairness of a trained model remains a challenging task. Revealing unfairness of machine learning models in interpretable fashion is a critical step towards fair and trustworthy AI. In this paper, we systematically tackle the novel task of revealing unfair models by mining interpretable evidence (RUMIE). The key idea is to find solid evidence in the form of a group of data instances discriminated most by the model. To make the evidence interpretable, we also find a set of human-understandable key attributes and decision rules that characterize the discriminated data instances and distinguish them from the other non-discriminated data. As demonstrated by extensive experiments on many real-world data sets, our method finds highly interpretable and solid evidence to effectively reveal the unfairness of trained models. Moreover, it is much more scalable than all of the baseline methods.