 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetrieval of Experiments with Sequential Dirichlet Process Mixtures in Model Space
Paper and Code
Mar 06, 2014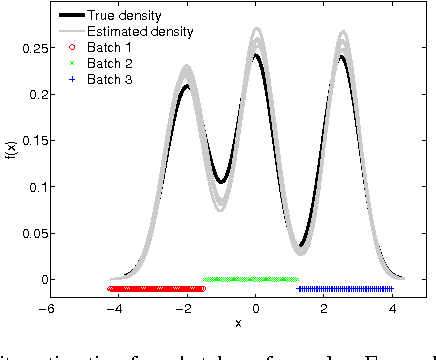
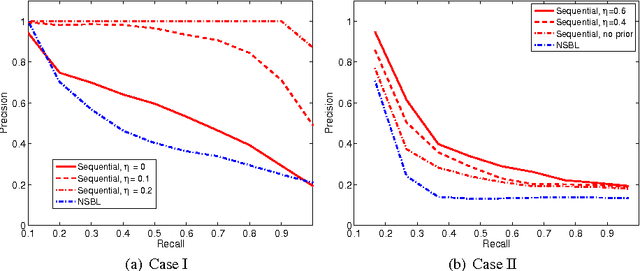
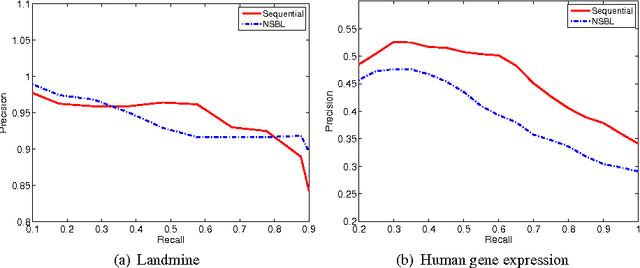
We address the problem of retrieving relevant experiments given a query experiment, motivated by the public databases of datasets in molecular biology and other experimental sciences, and the need of scientists to relate to earlier work on the level of actual measurement data. Since experiments are inherently noisy and databases ever accumulating, we argue that a retrieval engine should possess two particular characteristics. First, it should compare models learnt from the experiments rather than the raw measurements themselves: this allows incorporating experiment-specific prior knowledge to suppress noise effects and focus on what is important. Second, it should be updated sequentially from newly published experiments, without explicitly storing either the measurements or the models, which is critical for saving storage space and protecting data privacy: this promotes life long learning. We formulate the retrieval as a ``supermodelling'' problem, of sequentially learning a model of the set of posterior distributions, represented as sets of MCMC samples, and suggest the use of Particle-Learning-based sequential Dirichlet process mixture (DPM) for this purpose. The relevance measure for retrieval is derived from the supermodel through the mixture representation. We demonstrate the performance of the proposed retrieval method on simulated data and molecular biological experiments.