 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Generative Methods for Image Restoration in Physics-based Vision: A Theoretical Analysis from the Perspective of Information
Paper and Code
Dec 08, 2022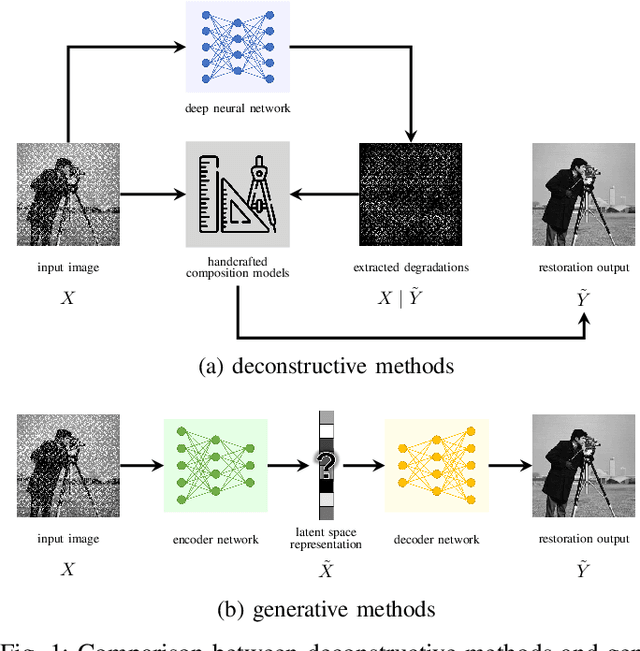
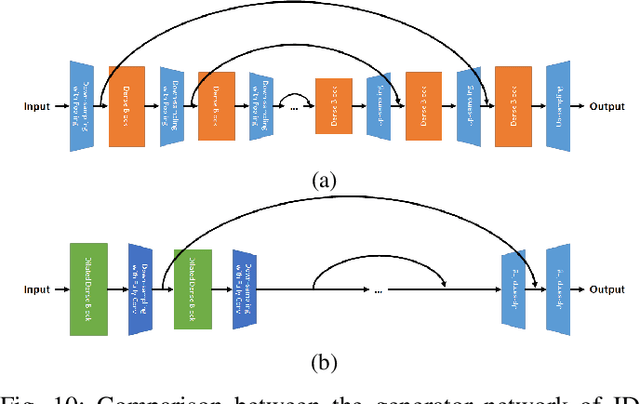
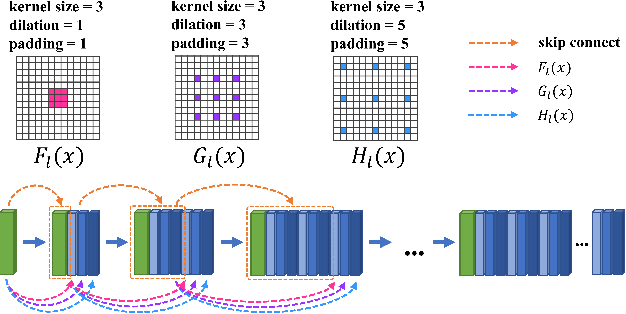
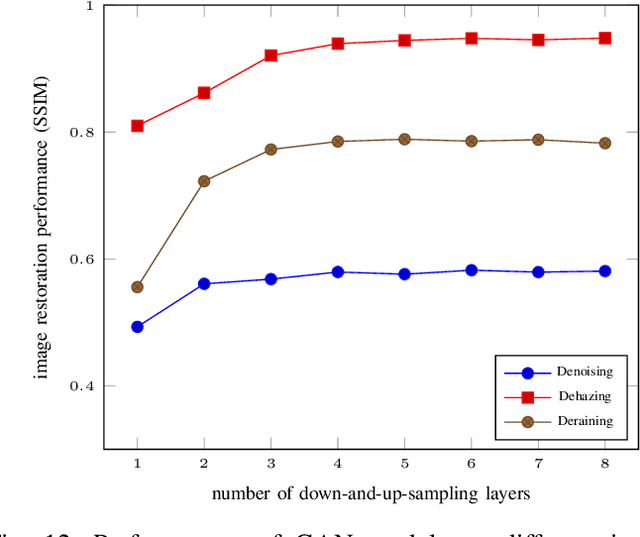
End-to-end generative methods are considered a more promising solution for image restoration in physics-based vision compared with the traditional deconstructive methods based on handcrafted composition models. However, existing generative methods still have plenty of room for improvement in quantitative performance. More crucially, these methods are considered black boxes due to weak interpretability and there is rarely a theory trying to explain their mechanism and learning process. In this study, we try to re-interpret these generative methods for image restoration tasks using information theory. Different from conventional understanding, we analyzed the information flow of these methods and identified three sources of information (extracted high-level information, retained low-level information, and external information that is absent from the source inputs) are involved and optimized respectively in generating the restoration results. We further derived their learning behaviors, optimization objectives, and the corresponding information boundaries by extending the information bottleneck principle. Based on this theoretic framework, we found that many existing generative methods tend to be direct applications of the general models designed for conventional generation tasks, which may suffer from problems including over-invested abstraction processes, inherent details loss, and vanishing gradients or imbalance in training. We analyzed these issues with both intuitive and theoretical explanations and proved them with empirical evidence respectively. Ultimately, we proposed general solutions or ideas to address the above issue and validated these approaches with performance boosts on six datasets of three different image restoration tasks.