 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Action Spaces for Reinforcement Learning in End-to-end Dialog Agents with Latent Variable Models
Paper and Code

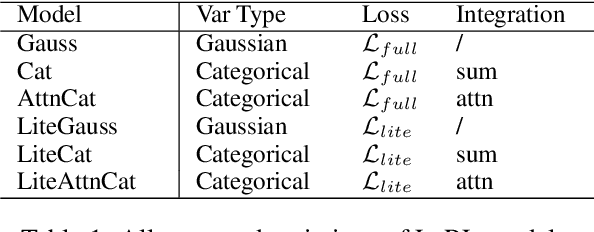


Defining action spaces for conversational agents and optimizing their decision-making process with reinforcement learning is an enduring challenge. Common practice has been to use handcrafted dialog acts, or the output vocabulary, e.g. in neural encoder decoders, as the action spaces. Both have their own limitations. This paper proposes a novel latent action framework that treats the action spaces of an end-to-end dialog agent as latent variables and develops unsupervised methods in order to induce its own action space from the data. Comprehensive experiments are conducted examining both continuous and discrete action types and two different optimization methods based on stochastic variational inference. Results show that the proposed latent actions achieve superior empirical performance improvement over previous word-level policy gradient methods on both DealOrNoDeal and MultiWoz dialogs. Our detailed analysis also provides insights about various latent variable approaches for policy learning and can serve as a foundation for developing better latent actions in future research.