 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResource and data efficient self supervised learning
Paper and Code
Sep 03, 2021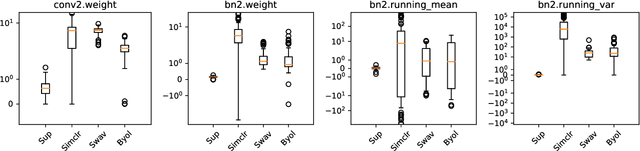
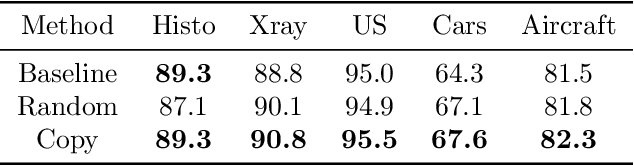
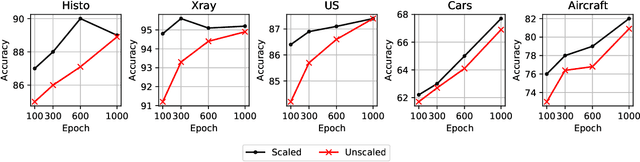
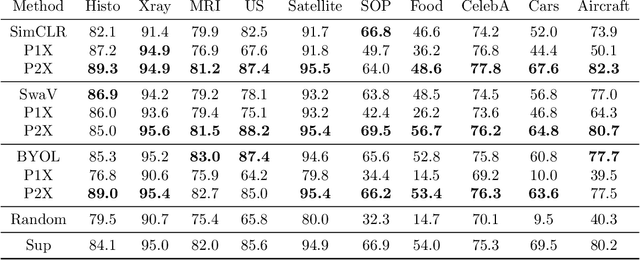
We investigate the utility of pretraining by contrastive self supervised learning on both natural-scene and medical imaging datasets when the unlabeled dataset size is small, or when the diversity within the unlabeled set does not lead to better representations. We use a two step approach which is analogous to supervised training with ImageNet initialization, where we pretrain networks that are already pretrained on ImageNet dataset to improve downstream task performance on the domain of interest. To improve the speed of convergence and the overall performance, we propose weight scaling and filter selection methods prior to second step of pretraining. We demonstrate the utility of this approach on three popular contrastive techniques, namely SimCLR, SWaV and BYOL. Benefits of double pretraining include better performance, faster convergence, ability to train with smaller batch sizes and smaller image dimensions with negligible differences in performance. We hope our work helps democratize self-supervision by enabling researchers to fine-tune models without requiring large clusters or long training times.