Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResKD: Residual-Guided Knowledge Distillation
Paper and Code
Jun 09, 2020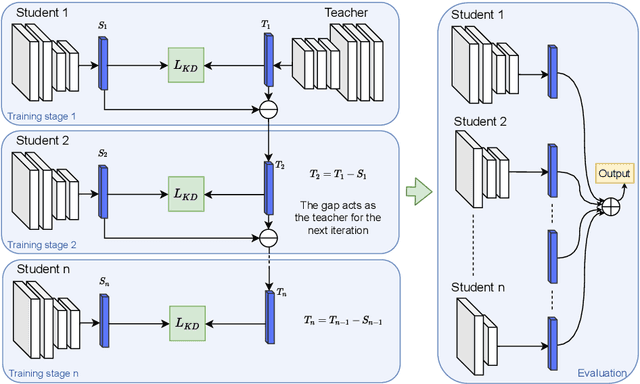
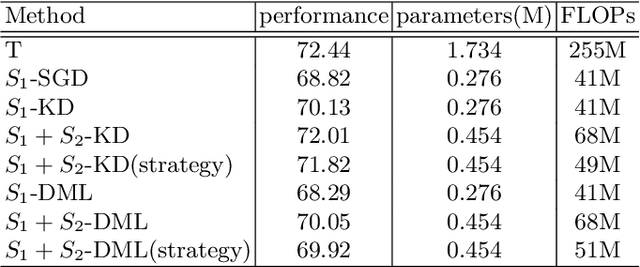
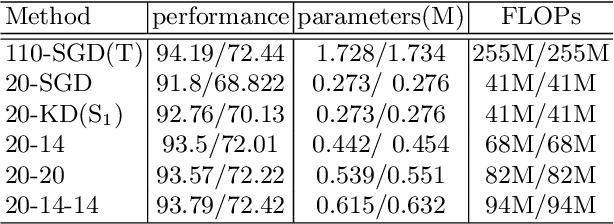
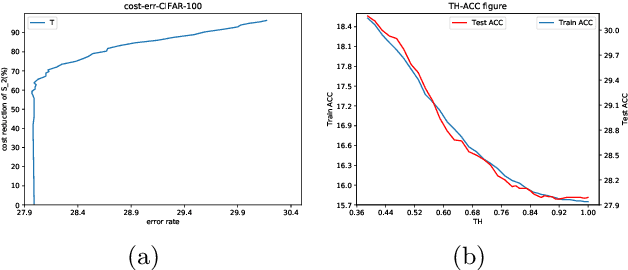
Knowledge distillation has emerged as a promising technique for compressing neural networks. Due to the capacity gap between a heavy teacher and a lightweight student, there exists a significant performance gap between them. In this paper, we see knowledge distillation in a fresh light, using the knowledge gap between a teacher and a student as guidance to train a lighter-weight student called res-student. The combination of a normal student and a res-student becomes a new student. Such a residual-guided process can be repeated. Experimental results show that we achieve competitive results on the CIFAR10/100, Tiny-ImageNet, and ImageNet datasets.
View paper on