 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResearch of Damped Newton Stochastic Gradient Descent Method for Neural Network Training
Paper and Code
Mar 31, 2021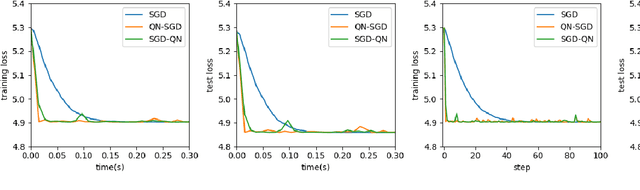
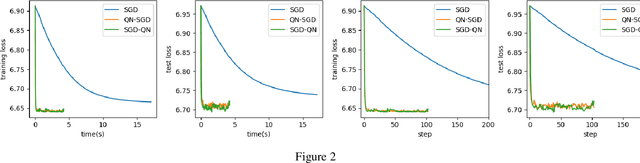
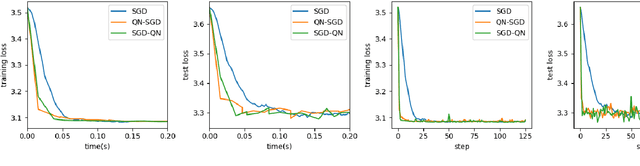

First-order methods like stochastic gradient descent(SGD) are recently the popular optimization method to train deep neural networks (DNNs), but second-order methods are scarcely used because of the overpriced computing cost in getting the high-order information. In this paper, we propose the Damped Newton Stochastic Gradient Descent(DN-SGD) method and Stochastic Gradient Descent Damped Newton(SGD-DN) method to train DNNs for regression problems with Mean Square Error(MSE) and classification problems with Cross-Entropy Loss(CEL), which is inspired by a proved fact that the hessian matrix of last layer of DNNs is always semi-definite. Different from other second-order methods to estimate the hessian matrix of all parameters, our methods just accurately compute a small part of the parameters, which greatly reduces the computational cost and makes convergence of the learning process much faster and more accurate than SGD. Several numerical experiments on real datesets are performed to verify the effectiveness of our methods for regression and classification problems.