 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReproducible Bootstrap Aggregating
Paper and Code
Jan 12, 2020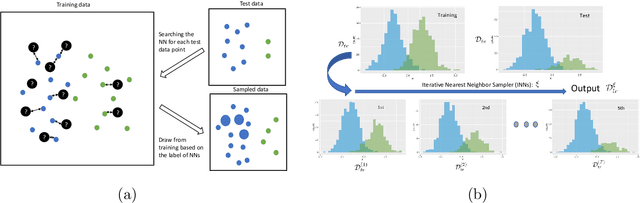

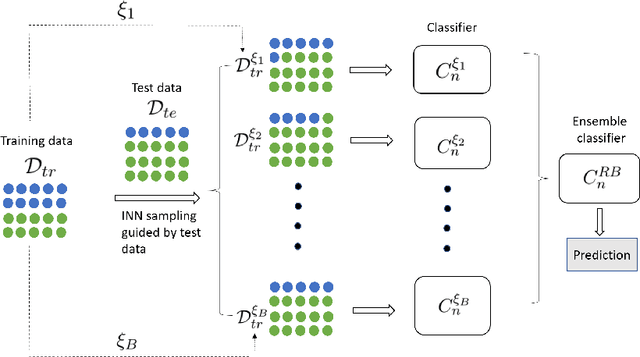
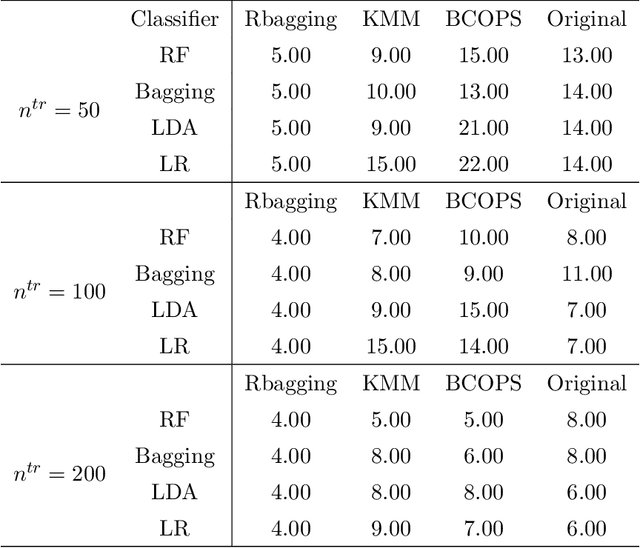
Heterogeneity between training and testing data degrades reproducibility of a well-trained predictive algorithm. In modern applications, how to deploy a trained algorithm in a different domain is becoming an urgent question raised by many domain scientists. In this paper, we propose a reproducible bootstrap aggregating (Rbagging) method coupled with a new algorithm, the iterative nearest neighbor sampler (INNs), effectively drawing bootstrap samples from training data to mimic the distribution of the test data. Rbagging is a general ensemble framework that can be applied to most classifiers. We further propose Rbagging+ to effectively detect anomalous samples in the testing data. Our theoretical results show that the resamples based on Rbagging have the same distribution as the testing data. Moreover, under suitable assumptions, we further provide a general bound to control the test excess risk of the ensemble classifiers. The proposed method is compared with several other popular domain adaptation methods via extensive simulation studies and real applications including medical diagnosis and imaging classifications.