 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepresentation Learning on Graphs: A Reinforcement Learning Application
Paper and Code
Jan 17, 2019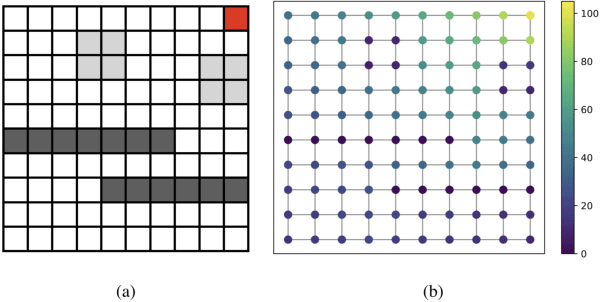
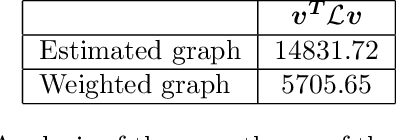
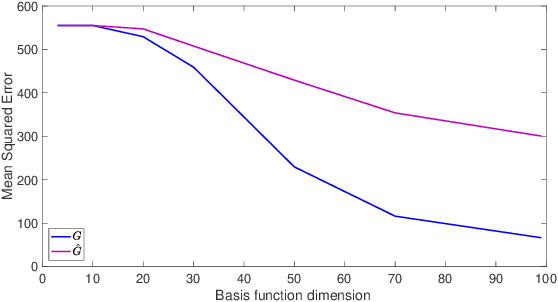
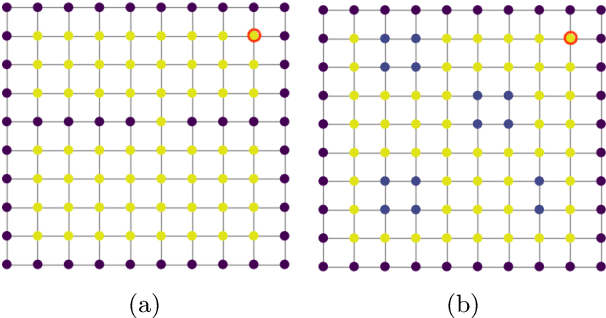
In this work, we study value function approximation in reinforcement learning (RL) problems with high dimensional state or action spaces via a generalized version of representation policy iteration (RPI). We consider the limitations of proto-value functions (PVFs) at accurately approximating the value function in low dimensions and we highlight the importance of features learning for an improved low-dimensional value function approximation. Then, we adopt different representation learning algorithm on graphs to learn the basis functions that best represent the value function. We empirically show that node2vec, an algorithm for scalable feature learning in networks, and the Variational Graph Auto-Encoder constantly outperform the commonly used smooth proto-value functions in low-dimensional feature space.