 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepresentation Gap in Deep Reinforcement Learning
Paper and Code
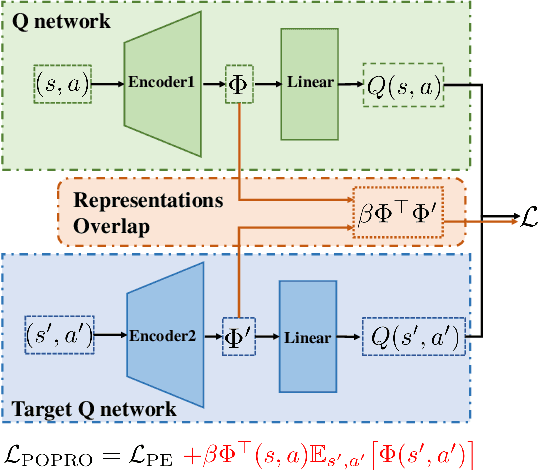

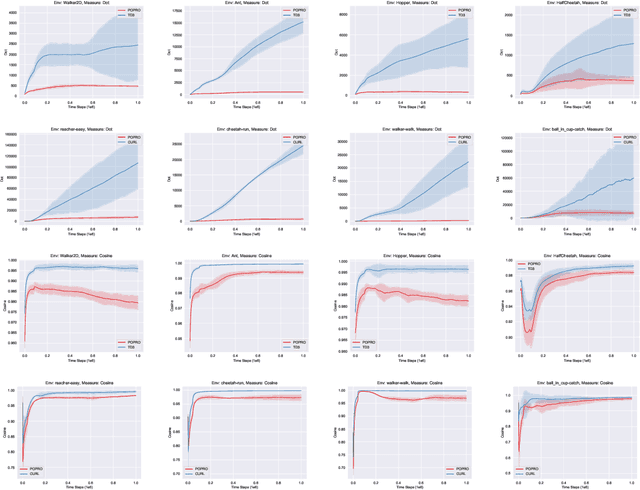

Deep reinforcement learning gives the promise that an agent learns good policy from high-dimensional information. Whereas representation learning removes irrelevant and redundant information and retains pertinent information. We consider the representation capacity of action value function and theoretically reveal its inherent property, \textit{representation gap} with its target action value function. This representation gap is favorable. However, through illustrative experiments, we show that the representation of action value function grows similarly compared with its target value function, i.e. the undesirable inactivity of the representation gap (\textit{representation overlap}). Representation overlap results in a loss of representation capacity, which further leads to sub-optimal learning performance. To activate the representation gap, we propose a simple but effective framework \underline{P}olicy \underline{O}ptimization from \underline{P}reventing \underline{R}epresentation \underline{O}verlaps (POPRO), which regularizes the policy evaluation phase through differing the representation of action value function from its target. We also provide the convergence rate guarantee of POPRO. We evaluate POPRO on gym continuous control suites. The empirical results show that POPRO using pixel inputs outperforms or parallels the sample-efficiency of methods that use state-based features.