 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRephrase and Respond: Let Large Language Models Ask Better Questions for Themselves
Paper and Code
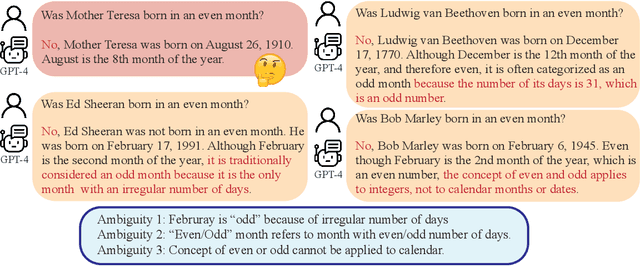
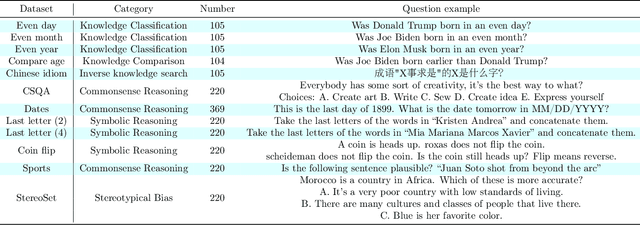


Misunderstandings arise not only in interpersonal communication but also between humans and Large Language Models (LLMs). Such discrepancies can make LLMs interpret seemingly unambiguous questions in unexpected ways, yielding incorrect responses. While it is widely acknowledged that the quality of a prompt, such as a question, significantly impacts the quality of the response provided by LLMs, a systematic method for crafting questions that LLMs can better comprehend is still underdeveloped. In this paper, we present a method named `Rephrase and Respond' (RaR), which allows LLMs to rephrase and expand questions posed by humans and provide responses in a single prompt. This approach serves as a simple yet effective prompting method for improving performance. We also introduce a two-step variant of RaR, where a rephrasing LLM first rephrases the question and then passes the original and rephrased questions together to a different responding LLM. This facilitates the effective utilization of rephrased questions generated by one LLM with another. Our experiments demonstrate that our methods significantly improve the performance of different models across a wide range to tasks. We further provide a comprehensive comparison between RaR and the popular Chain-of-Thought (CoT) methods, both theoretically and empirically. We show that RaR is complementary to CoT and can be combined with CoT to achieve even better performance. Our work not only contributes to enhancing LLM performance efficiently and effectively but also sheds light on a fair evaluation of LLM capabilities. Data and codes are available at https://github.com/uclaml/Rephrase-and-Respond.