 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRemovable and/or Repeated Units Emerge in Overparametrized Deep Neural Networks
Paper and Code



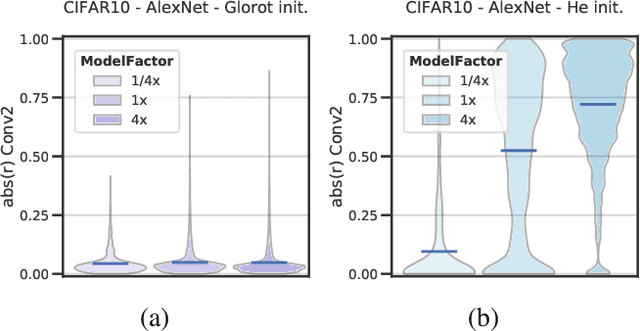
Deep neural networks (DNNs) perform well on a variety of tasks despite the fact that most networks used in practice are vastly overparametrized and even capable of perfectly fitting randomly labeled data. Recent evidence suggests that developing compressible representations is key for adjusting the complexity of overparametrized networks to the task at hand. In this paper, we provide new empirical evidence that supports this hypothesis by identifying two types of units that emerge when the network's width is increased: removable units which can be dropped out of the network without significant change to the output and repeated units whose activities are highly correlated with other units. The emergence of these units implies capacity constraints as the function the network represents could be expressed by a smaller network without these units. In a series of experiments with AlexNet, ResNet and Inception networks in the CIFAR-10 and ImageNet datasets, and also using shallow networks with synthetic data, we show that DNNs consistently increase either the number of removable units, repeated units, or both at greater widths for a comprehensive set of hyperparameters. These results suggest that the mechanisms by which networks in the deep learning regime adjust their complexity operate at the unit level and highlight the need for additional research into what drives the emergence of such units.