 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelevant Attributes in Formal Contexts
Paper and Code
Dec 20, 2018

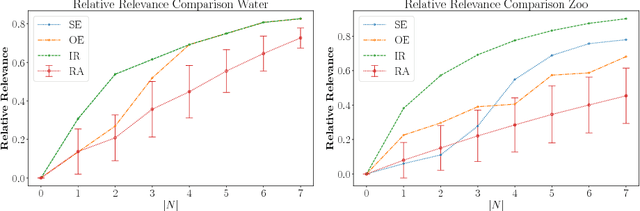

Computing conceptual structures, like formal concept lattices, is in the age of massive data sets a challenging task. There are various approaches to deal with this, e.g., random sampling, parallelization, or attribute extraction. A so far not investigated method in the realm of formal concept analysis is attribute selection, as done in machine learning. Building up on this we introduce a method for attribute selection in formal contexts. To this end, we propose the notion of relevant attributes which enables us to define a relative relevance function, reflecting both the order structure of the concept lattice as well as distribution of objects on it. Finally, we overcome computational challenges for computing the relative relevance through an approximation approach based on information entropy.