 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelational Autoencoder for Feature Extraction
Paper and Code
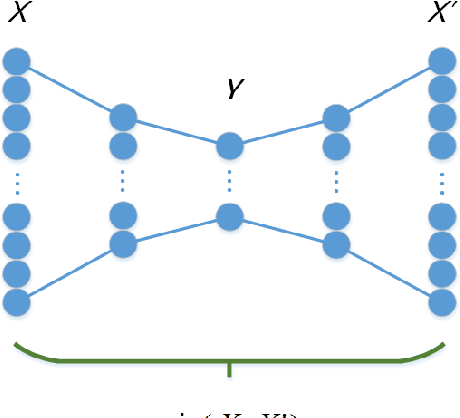
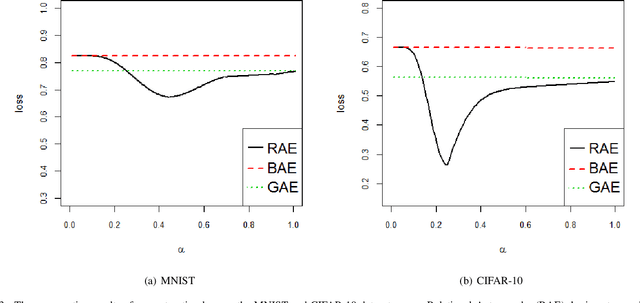
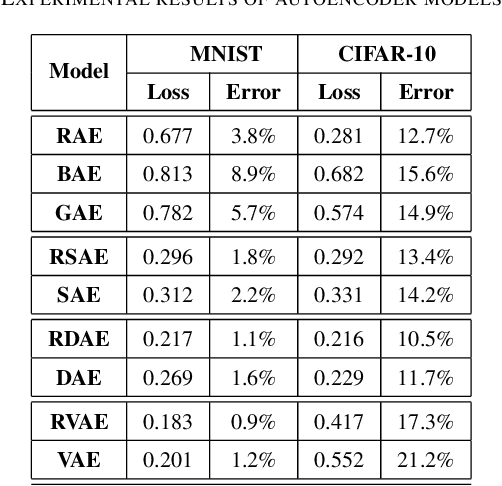
Feature extraction becomes increasingly important as data grows high dimensional. Autoencoder as a neural network based feature extraction method achieves great success in generating abstract features of high dimensional data. However, it fails to consider the relationships of data samples which may affect experimental results of using original and new features. In this paper, we propose a Relation Autoencoder model considering both data features and their relationships. We also extend it to work with other major autoencoder models including Sparse Autoencoder, Denoising Autoencoder and Variational Autoencoder. The proposed relational autoencoder models are evaluated on a set of benchmark datasets and the experimental results show that considering data relationships can generate more robust features which achieve lower construction loss and then lower error rate in further classification compared to the other variants of autoencoders.