 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning with Heterogeneous Data: Estimation and Inference
Paper and Code
Jan 31, 2022


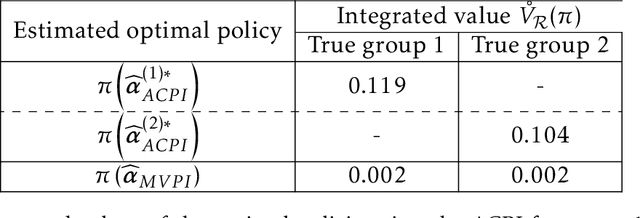
Reinforcement Learning (RL) has the promise of providing data-driven support for decision-making in a wide range of problems in healthcare, education, business, and other domains. Classical RL methods focus on the mean of the total return and, thus, may provide misleading results in the setting of the heterogeneous populations that commonly underlie large-scale datasets. We introduce the K-Heterogeneous Markov Decision Process (K-Hetero MDP) to address sequential decision problems with population heterogeneity. We propose the Auto-Clustered Policy Evaluation (ACPE) for estimating the value of a given policy, and the Auto-Clustered Policy Iteration (ACPI) for estimating the optimal policy in a given policy class. Our auto-clustered algorithms can automatically detect and identify homogeneous sub-populations, while estimating the Q function and the optimal policy for each sub-population. We establish convergence rates and construct confidence intervals for the estimators obtained by the ACPE and ACPI. We present simulations to support our theoretical findings, and we conduct an empirical study on the standard MIMIC-III dataset. The latter analysis shows evidence of value heterogeneity and confirms the advantages of our new method.