 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning with Generative Models for Compact Support Sets
Paper and Code
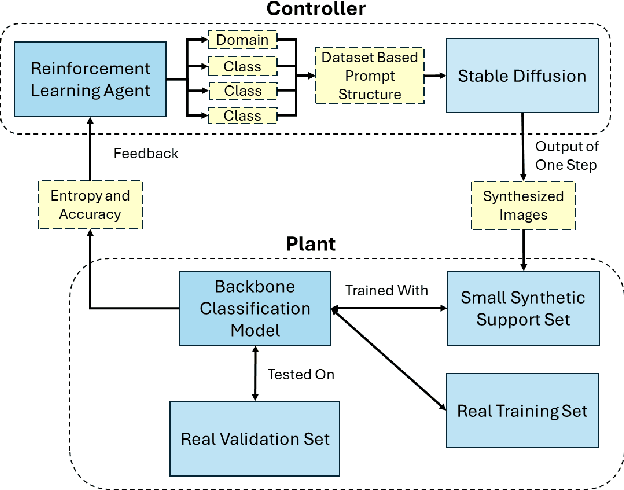



Foundation models contain a wealth of information from their vast number of training samples. However, most prior arts fail to extract this information in a precise and efficient way for small sample sizes. In this work, we propose a framework utilizing reinforcement learning as a control for foundation models, allowing for the granular generation of small, focused synthetic support sets to augment the performance of neural network models on real data classification tasks. We first allow a reinforcement learning agent access to a novel context based dictionary; the agent then uses this dictionary with a novel prompt structure to form and optimize prompts as inputs to generative models, receiving feedback based on a reward function combining the change in validation accuracy and entropy. A support set is formed this way over several exploration steps. Our framework produced excellent results, increasing classification accuracy by significant margins for no additional labelling or data cost.