Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning under Drift
Paper and Code
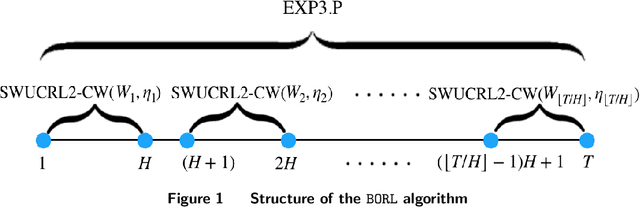

We propose algorithms with state-of-the-art \emph{dynamic regret} bounds for un-discounted reinforcement learning under drifting non-stationarity, where both the reward functions and state transition distributions are allowed to evolve over time. Our main contributions are: 1) A tuned Sliding Window Upper-Confidence bound for Reinforcement Learning with Confidence-Widening (\texttt{SWUCRL2-CW}) algorithm, which attains low dynamic regret bounds against the optimal non-stationary policy in various cases. 2) The Bandit-over-Reinforcement Learning (\texttt{BORL}) framework that further permits us to enjoy these dynamic regret bounds in a parameter-free manner.
View paper on