 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning of Structured Control for Linear Systems with Unknown State Matrix
Paper and Code
Nov 02, 2020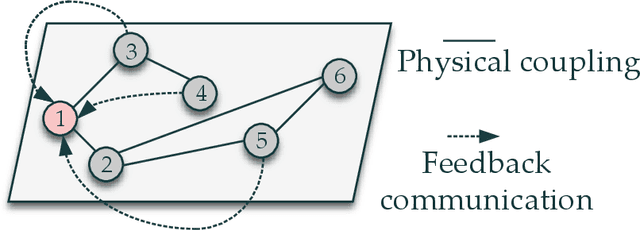
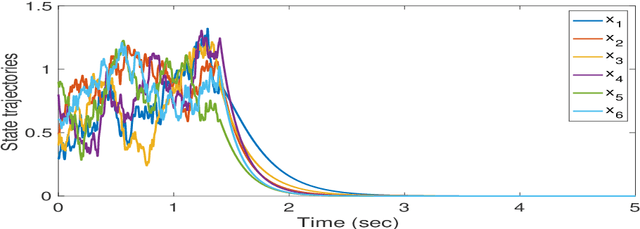


This paper delves into designing stabilizing feedback control gains for continuous linear systems with unknown state matrix, in which the control is subject to a general structural constraint. We bring forth the ideas from reinforcement learning (RL) in conjunction with sufficient stability and performance guarantees in order to design these structured gains using the trajectory measurements of states and controls. We first formulate a model-based framework using dynamic programming (DP) to embed the structural constraint to the Linear Quadratic Regulator (LQR) gain computation in the continuous-time setting. Subsequently, we transform this LQR formulation into a policy iteration RL algorithm that can alleviate the requirement of known state matrix in conjunction with maintaining the feedback gain structure. Theoretical guarantees are provided for stability and convergence of the structured RL (SRL) algorithm. The introduced RL framework is general and can be applied to any control structure. A special control structure enabled by this RL framework is distributed learning control which is necessary for many large-scale cyber-physical systems. As such, we validate our theoretical results with numerical simulations on a multi-agent networked linear time-invariant (LTI) dynamic system.