 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning for UAV Attitude Control
Paper and Code
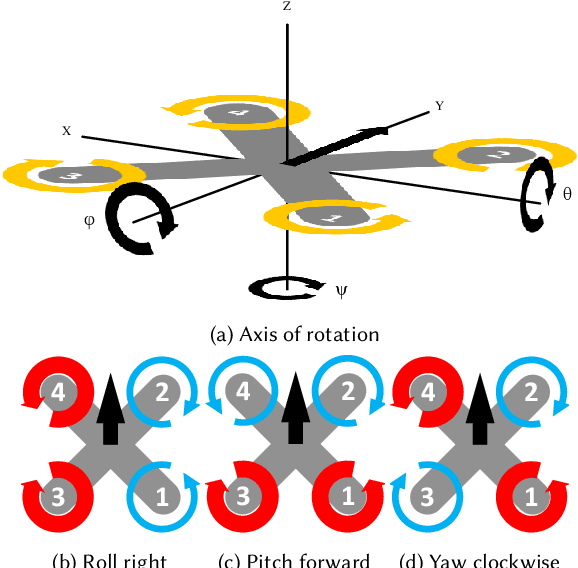
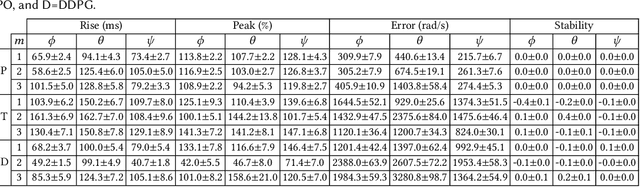
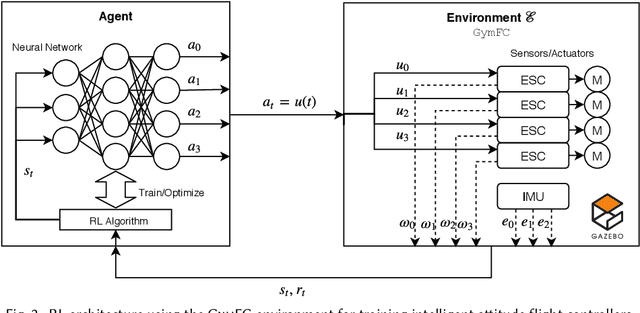
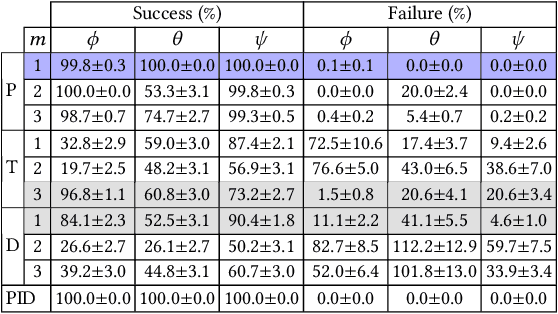
Autopilot systems are typically composed of an "inner loop" providing stability and control, while an "outer loop" is responsible for mission-level objectives, e.g. way-point navigation. Autopilot systems for UAVs are predominately implemented using Proportional, Integral Derivative (PID) control systems, which have demonstrated exceptional performance in stable environments. However more sophisticated control is required to operate in unpredictable, and harsh environments. Intelligent flight control systems is an active area of research addressing limitations of PID control most recently through the use of reinforcement learning (RL) which has had success in other applications such as robotics. However previous work has focused primarily on using RL at the mission-level controller. In this work, we investigate the performance and accuracy of the inner control loop providing attitude control when using intelligent flight control systems trained with the state-of-the-art RL algorithms, Deep Deterministic Gradient Policy (DDGP), Trust Region Policy Optimization (TRPO) and Proximal Policy Optimization (PPO). To investigate these unknowns we first developed an open-source high-fidelity simulation environment to train a flight controller attitude control of a quadrotor through RL. We then use our environment to compare their performance to that of a PID controller to identify if using RL is appropriate in high-precision, time-critical flight control.