 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning for Node Selection in Branch-and-Bound
Paper and Code
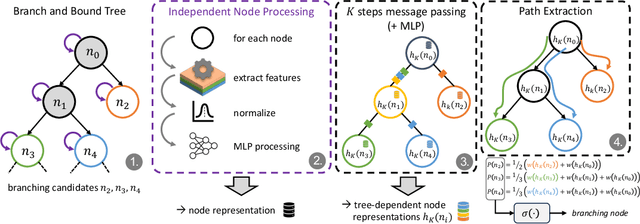


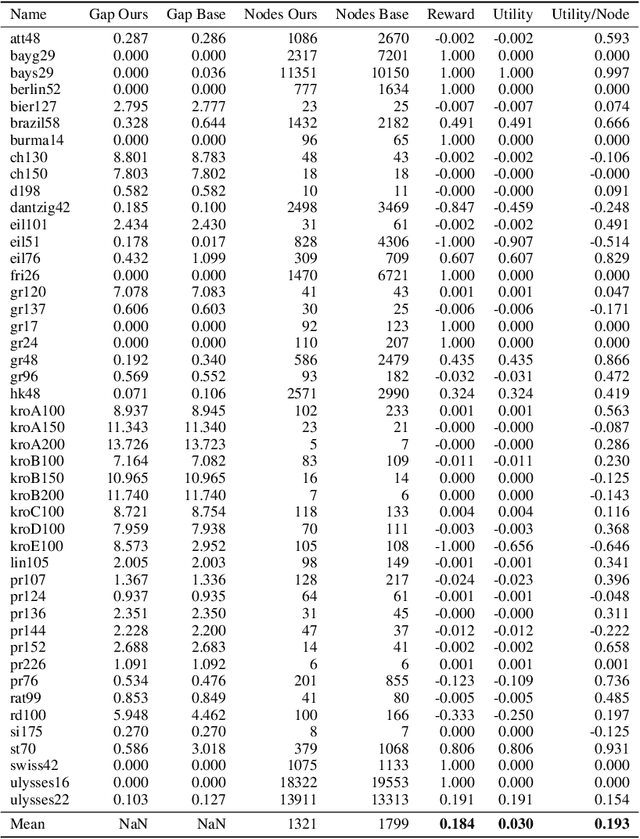
A big challenge in branch and bound lies in identifying the optimal node within the search tree from which to proceed. Current state-of-the-art selectors utilize either hand-crafted ensembles that automatically switch between naive sub-node selectors, or learned node selectors that rely on individual node data. We propose a novel bi-simulation technique that uses reinforcement learning (RL) while considering the entire tree state, rather than just isolated nodes. To achieve this, we train a graph neural network that produces a probability distribution based on the path from the model's root to its ``to-be-selected'' leaves. Modelling node-selection as a probability distribution allows us to train the model using state-of-the-art RL techniques that capture both intrinsic node-quality and node-evaluation costs. Our method induces a high quality node selection policy on a set of varied and complex problem sets, despite only being trained on specially designed, synthetic TSP instances. Experiments on several benchmarks show significant improvements in optimality gap reductions and per-node efficiency under strict time constraints.