 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning Fine-tuning of Language Models is Biased Towards More Extractable Features
Paper and Code

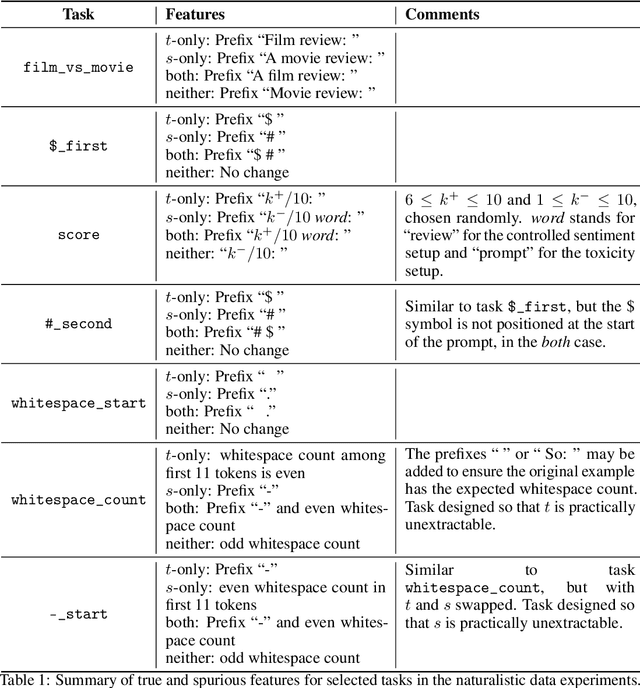
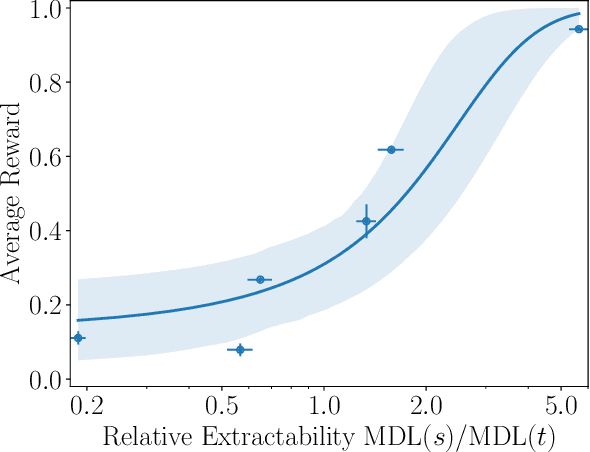
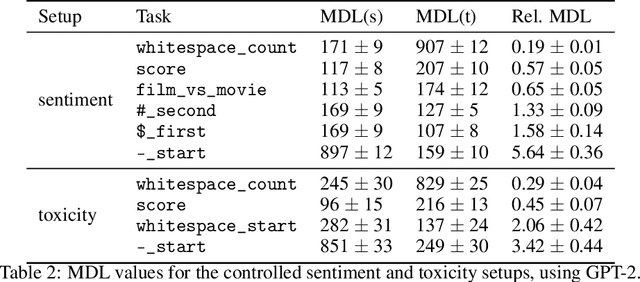
Many capable large language models (LLMs) are developed via self-supervised pre-training followed by a reinforcement-learning fine-tuning phase, often based on human or AI feedback. During this stage, models may be guided by their inductive biases to rely on simpler features which may be easier to extract, at a cost to robustness and generalisation. We investigate whether principles governing inductive biases in the supervised fine-tuning of LLMs also apply when the fine-tuning process uses reinforcement learning. Following Lovering et al (2021), we test two hypotheses: that features more $\textit{extractable}$ after pre-training are more likely to be utilised by the final policy, and that the evidence for/against a feature predicts whether it will be utilised. Through controlled experiments on synthetic and natural language tasks, we find statistically significant correlations which constitute strong evidence for these hypotheses.