 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegularizing Recurrent Networks - On Injected Noise and Norm-based Methods
Paper and Code
Oct 21, 2014


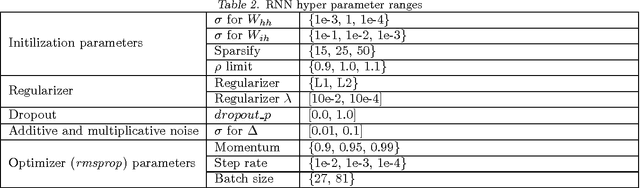
Advancements in parallel processing have lead to a surge in multilayer perceptrons' (MLP) applications and deep learning in the past decades. Recurrent Neural Networks (RNNs) give additional representational power to feedforward MLPs by providing a way to treat sequential data. However, RNNs are hard to train using conventional error backpropagation methods because of the difficulty in relating inputs over many time-steps. Regularization approaches from MLP sphere, like dropout and noisy weight training, have been insufficiently applied and tested on simple RNNs. Moreover, solutions have been proposed to improve convergence in RNNs but not enough to improve the long term dependency remembering capabilities thereof. In this study, we aim to empirically evaluate the remembering and generalization ability of RNNs on polyphonic musical datasets. The models are trained with injected noise, random dropout, norm-based regularizers and their respective performances compared to well-initialized plain RNNs and advanced regularization methods like fast-dropout. We conclude with evidence that training with noise does not improve performance as conjectured by a few works in RNN optimization before ours.