 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegularized Laplacian Estimation and Fast Eigenvector Approximation
Paper and Code
Oct 11, 2011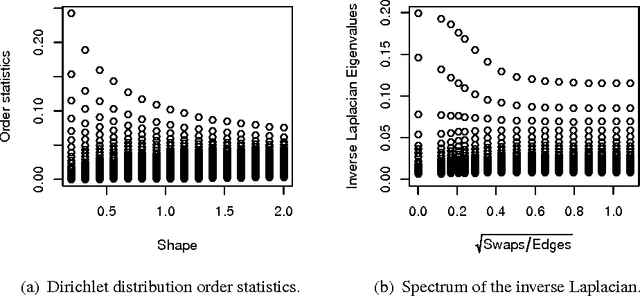
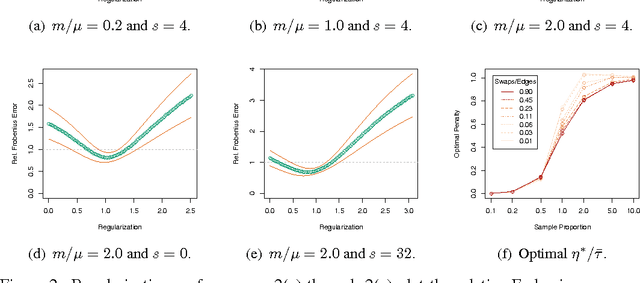
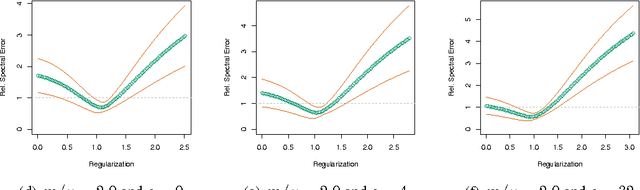
Recently, Mahoney and Orecchia demonstrated that popular diffusion-based procedures to compute a quick \emph{approximation} to the first nontrivial eigenvector of a data graph Laplacian \emph{exactly} solve certain regularized Semi-Definite Programs (SDPs). In this paper, we extend that result by providing a statistical interpretation of their approximation procedure. Our interpretation will be analogous to the manner in which $\ell_2$-regularized or $\ell_1$-regularized $\ell_2$-regression (often called Ridge regression and Lasso regression, respectively) can be interpreted in terms of a Gaussian prior or a Laplace prior, respectively, on the coefficient vector of the regression problem. Our framework will imply that the solutions to the Mahoney-Orecchia regularized SDP can be interpreted as regularized estimates of the pseudoinverse of the graph Laplacian. Conversely, it will imply that the solution to this regularized estimation problem can be computed very quickly by running, e.g., the fast diffusion-based PageRank procedure for computing an approximation to the first nontrivial eigenvector of the graph Laplacian. Empirical results are also provided to illustrate the manner in which approximate eigenvector computation \emph{implicitly} performs statistical regularization, relative to running the corresponding exact algorithm.