 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegularized Forward-Backward Decoder for Attention Models
Paper and Code
Jun 15, 2020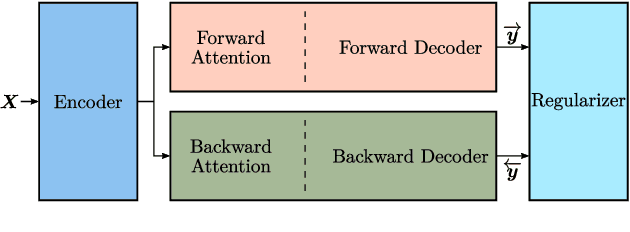
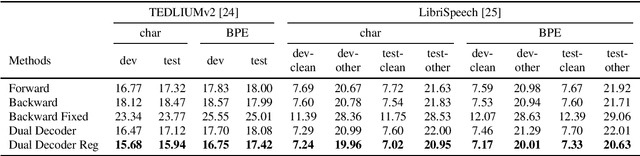
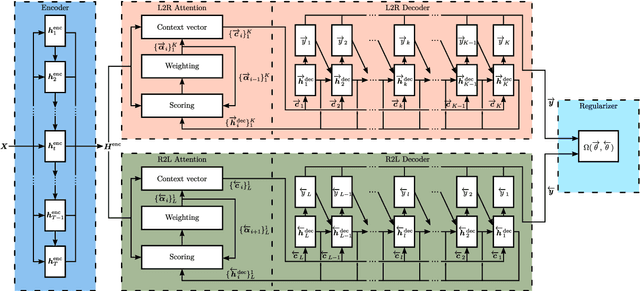
Nowadays, attention models are one of the popular candidates for speech recognition. So far, many studies mainly focus on the encoder structure or the attention module to enhance the performance of these models. However, mostly ignore the decoder. In this paper, we propose a novel regularization technique incorporating a second decoder during the training phase. This decoder is optimized on time-reversed target labels beforehand and supports the standard decoder during training by adding knowledge from future context. Since it is only added during training, we are not changing the basic structure of the network or adding complexity during decoding. We evaluate our approach on the smaller TEDLIUMv2 and the larger LibriSpeech dataset, achieving consistent improvements on both of them.