 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegret Analysis in Deterministic Reinforcement Learning
Paper and Code
Jun 27, 2021
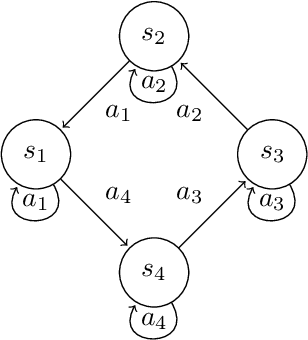
We consider Markov Decision Processes (MDPs) with deterministic transitions and study the problem of regret minimization, which is central to the analysis and design of optimal learning algorithms. We present logarithmic problem-specific regret lower bounds that explicitly depend on the system parameter (in contrast to previous minimax approaches) and thus, truly quantify the fundamental limit of performance achievable by any learning algorithm. Deterministic MDPs can be interpreted as graphs and analyzed in terms of their cycles, a fact which we leverage in order to identify a class of deterministic MDPs whose regret lower bound can be determined numerically. We further exemplify this result on a deterministic line search problem, and a deterministic MDP with state-dependent rewards, whose regret lower bounds we can state explicitly. These bounds share similarities with the known problem-specific bound of the multi-armed bandit problem and suggest that navigation on a deterministic MDP need not have an effect on the performance of a learning algorithm.