 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegion Detection in Markov Random Fields: Gaussian Case
Paper and Code
Mar 29, 2018


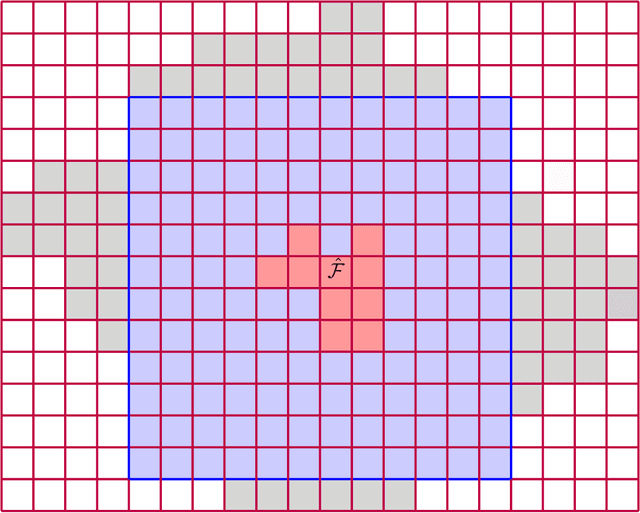
We consider the problem of model selection in Gaussian Markov fields in the sample deficient scenario. The benchmark information-theoretic results in the case of d-regular graphs require the number of samples to be at least proportional to the logarithm of the number of vertices to allow consistent graph recovery. When the number of samples is less than this amount, reliable detection of all edges is impossible. In many applications, it is more important to learn the distribution of the edge (coupling) parameters over the network than the specific locations of the edges. Assuming that the entire graph can be partitioned into a number of spatial regions with similar edge parameters and reasonably regular boundaries, we develop new information-theoretic sample complexity bounds and show that a bounded number of samples can be sufficient to consistently recover these regions. Finally, we introduce and analyze an efficient region growing algorithm capable of recovering the regions with high accuracy. We show that it is consistent and demonstrate its performance benefits in synthetic simulations.