 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRefining Skewed Perceptions in Vision-Language Models through Visual Representations
Paper and Code
May 22, 2024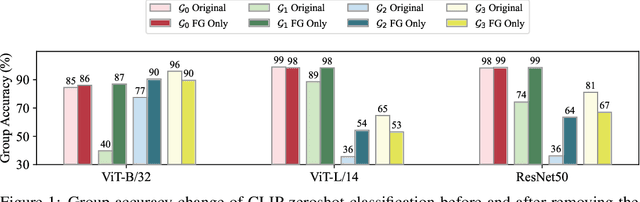

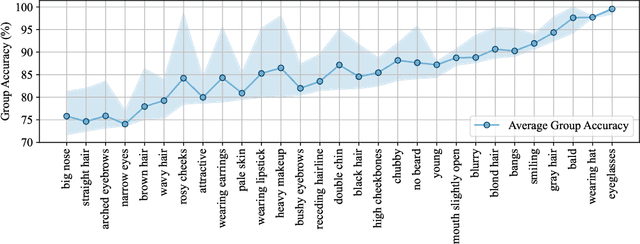
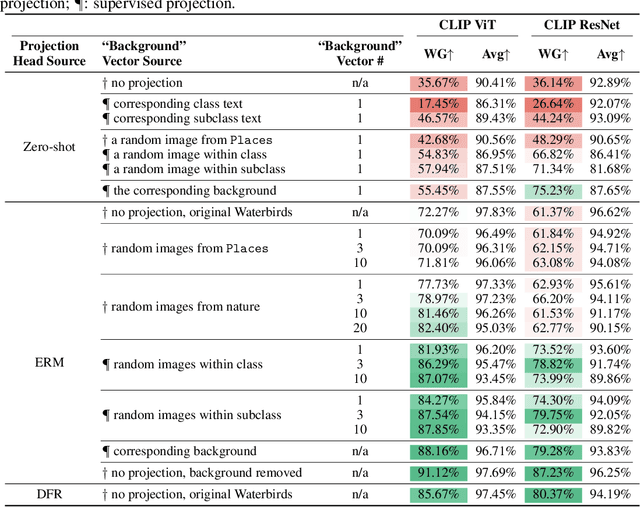
Large vision-language models (VLMs), such as CLIP, have become foundational, demonstrating remarkable success across a variety of downstream tasks. Despite their advantages, these models, akin to other foundational systems, inherit biases from the disproportionate distribution of real-world data, leading to misconceptions about the actual environment. Prevalent datasets like ImageNet are often riddled with non-causal, spurious correlations that can diminish VLM performance in scenarios where these contextual elements are absent. This study presents an investigation into how a simple linear probe can effectively distill task-specific core features from CLIP's embedding for downstream applications. Our analysis reveals that the CLIP text representations are often tainted by spurious correlations, inherited in the biased pre-training dataset. Empirical evidence suggests that relying on visual representations from CLIP, as opposed to text embedding, is more practical to refine the skewed perceptions in VLMs, emphasizing the superior utility of visual representations in overcoming embedded biases. Our codes will be available here.