 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReducing the error of Monte Carlo Algorithms by Learning Control Variates
Paper and Code
Jun 07, 2016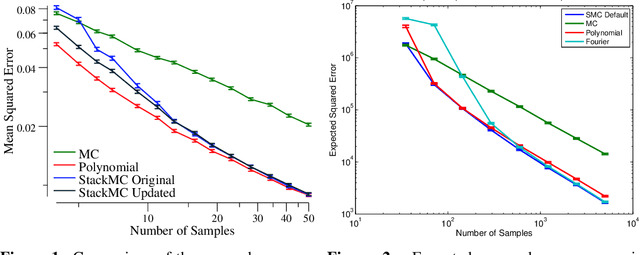
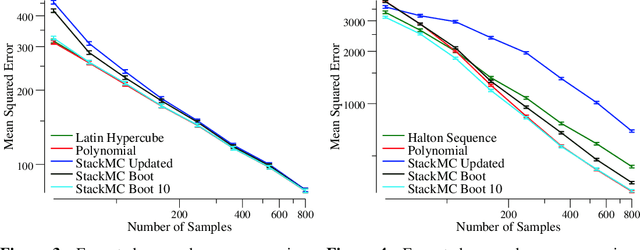
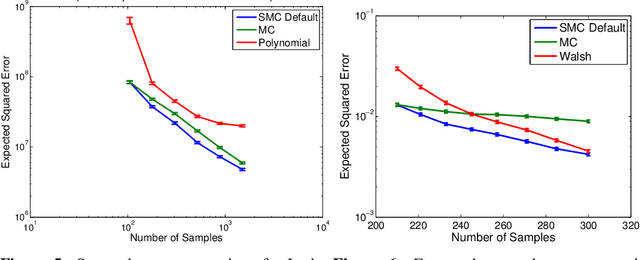
Monte Carlo (MC) sampling algorithms are an extremely widely-used technique to estimate expectations of functions f(x), especially in high dimensions. Control variates are a very powerful technique to reduce the error of such estimates, but in their conventional form rely on having an accurate approximation of f, a priori. Stacked Monte Carlo (StackMC) is a recently introduced technique designed to overcome this limitation by fitting a control variate to the data samples themselves. Done naively, forming a control variate to the data would result in overfitting, typically worsening the MC algorithm's performance. StackMC uses in-sample / out-sample techniques to remove this overfitting. Crucially, it is a post-processing technique, requiring no additional samples, and can be applied to data generated by any MC estimator. Our preliminary experiments demonstrated that StackMC improved the estimates of expectations when it was used to post-process samples produces by a "simple sampling" MC estimator. Here we substantially extend this earlier work. We provide an in-depth analysis of the StackMC algorithm, which we use to construct an improved version of the original algorithm, with lower estimation error. We then perform experiments of StackMC on several additional kinds of MC estimators, demonstrating improved performance when the samples are generated via importance sampling, Latin-hypercube sampling and quasi-Monte Carlo sampling. We also show how to extend StackMC to combine multiple fitting functions, and how to apply it to discrete input spaces x.