 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReducing Language Biases in Visual Question Answering with Visually-Grounded Question Encoder
Paper and Code
Jul 18, 2020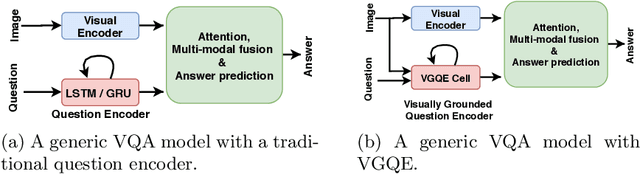
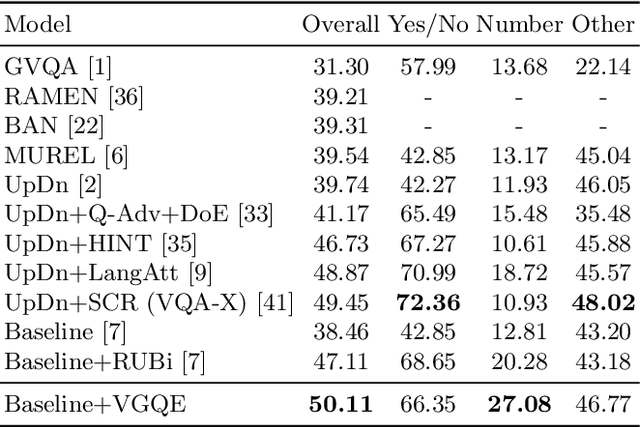
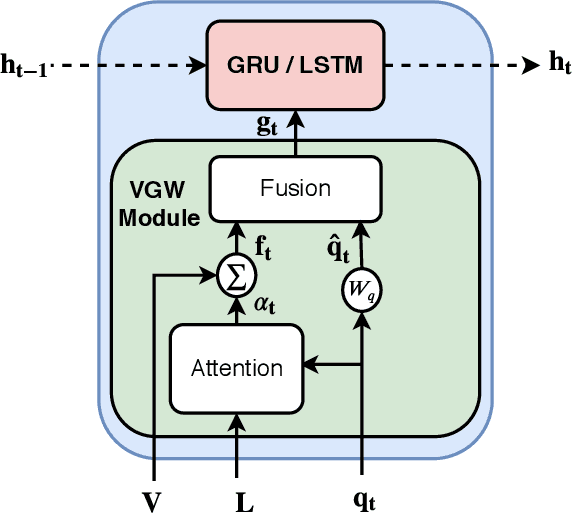
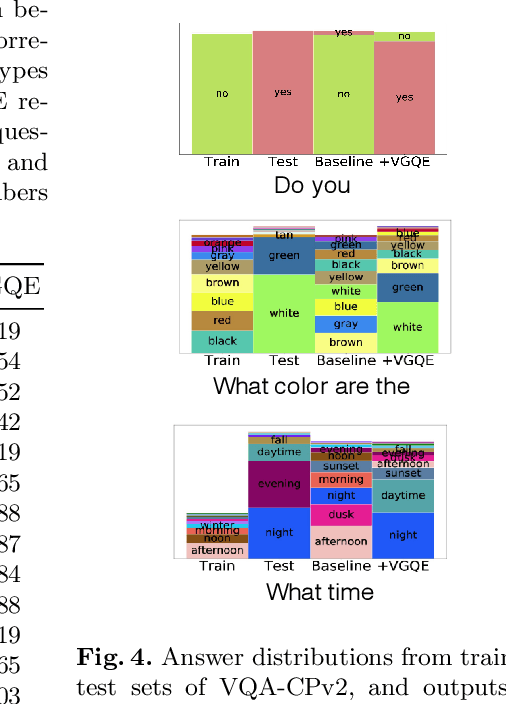
Recent studies have shown that current VQA models are heavily biased on the language priors in the train set to answer the question, irrespective of the image. E.g., overwhelmingly answer "what sport is" as "tennis" or "what color banana" as "yellow." This behavior restricts them from real-world application scenarios. In this work, we propose a novel model-agnostic question encoder, Visually-Grounded Question Encoder (VGQE), for VQA that reduces this effect. VGQE utilizes both visual and language modalities equally while encoding the question. Hence the question representation itself gets sufficient visual-grounding, and thus reduces the dependency of the model on the language priors. We demonstrate the effect of VGQE on three recent VQA models and achieve state-of-the-art results on the bias-sensitive split of the VQAv2 dataset; VQA-CPv2. Further, unlike the existing bias-reduction techniques, on the standard VQAv2 benchmark, our approach does not drop the accuracy; instead, it improves the performance.