 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReduced-Gate Convolutional LSTM Using Predictive Coding for Spatiotemporal Prediction
Paper and Code
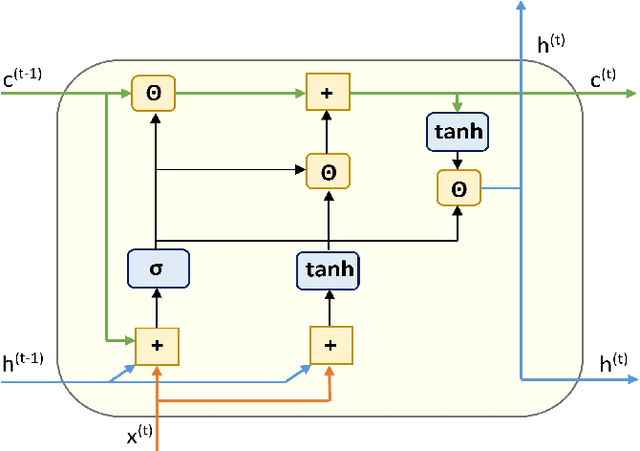
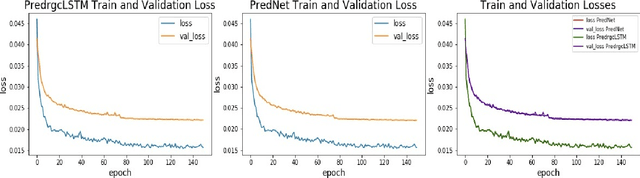
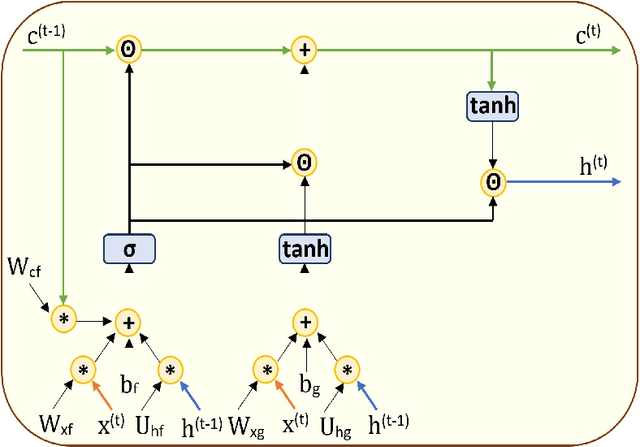
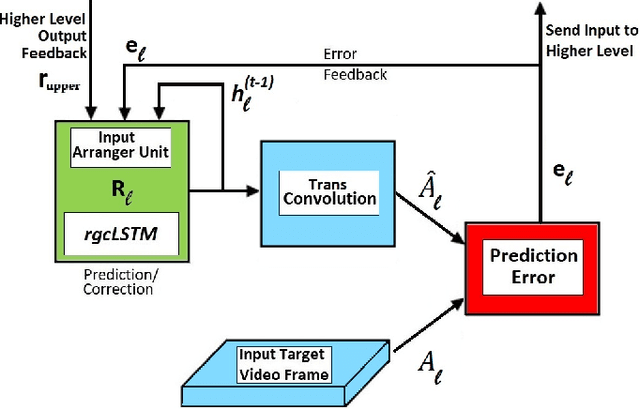
Spatiotemporal sequence prediction is an important problem in deep learning. We study next-frame(s) video prediction using a deep-learning-based predictive coding framework that uses convolutional, long short-term memory (convLSTM) modules. We introduce a novel reduced-gate convolutional LSTM (rgcLSTM) architecture that requires a significantly lower parameter budget than a comparable convLSTM. Our reduced-gate model achieves equal or better next-frame(s) prediction accuracy than the original convolutional LSTM while using a smaller parameter budget, thereby reducing training time. We tested our reduced gate modules within a predictive coding architecture on the moving MNIST and KITTI datasets. We found that our reduced-gate model has a significant reduction of approximately 40 percent of the total number of training parameters and a 25 percent redution in elapsed training time in comparison with the standard convolutional LSTM model. This makes our model more attractive for hardware implementation especially on small devices.