 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecursive Visual Attention in Visual Dialog
Paper and Code

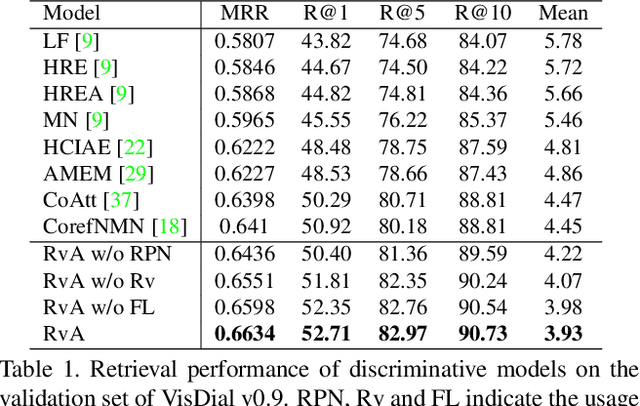
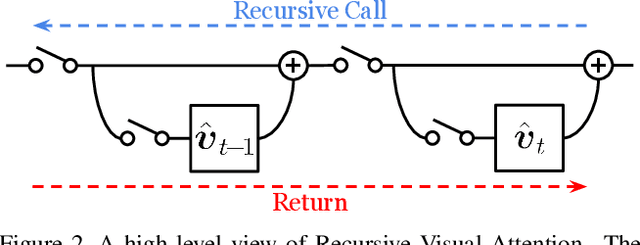

Visual dialog is a challenging vision-language task, which requires the agent to answer multi-round questions about an image. It typically needs to address two major problems: (1) How to answer visually-grounded questions, which is the core challenge in visual question answering (VQA); (2) How to infer the co-reference between questions and the dialog history. An example of visual co-reference is: pronouns (e.g., `they') in the question (e.g., `Are they on or off?') are linked with nouns (e.g., `lamps') appearing in the dialog history (e.g., `How many lamps are there?') and the object grounded in the image. In this work, to resolve the visual co-reference for visual dialog, we propose a novel attention mechanism called Recursive Visual Attention (RvA). Specifically, our dialog agent browses the dialog history until the agent has sufficient confidence in the visual co-reference resolution, and refines the visual attention recursively. The quantitative and qualitative experimental results on the large-scale VisDial v0.9 and v1.0 datasets demonstrate that the proposed RvA not only outperforms the state-of-the-art methods, but also achieves reasonable recursion and interpretable attention maps without additional annotations.