 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecursive Least Squares Advantage Actor-Critic Algorithms
Paper and Code
Jan 15, 2022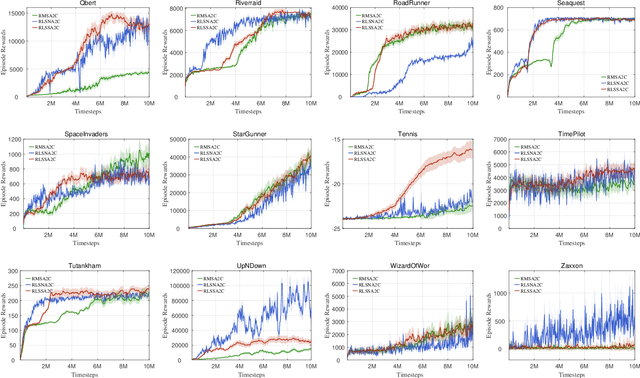
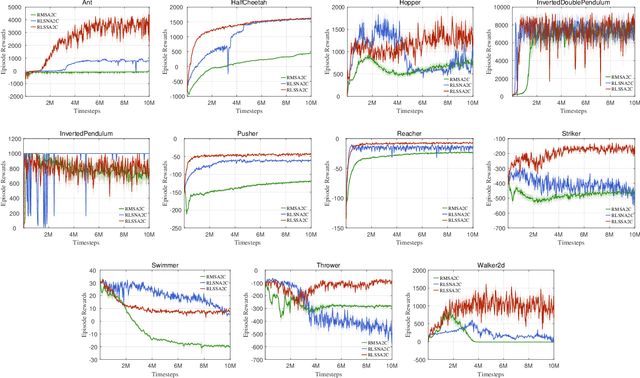
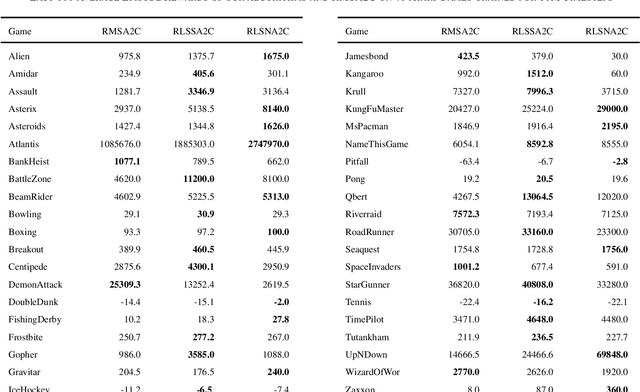
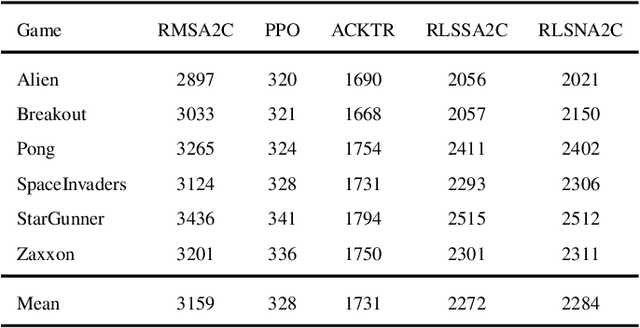
As an important algorithm in deep reinforcement learning, advantage actor critic (A2C) has been widely succeeded in both discrete and continuous control tasks with raw pixel inputs, but its sample efficiency still needs to improve more. In traditional reinforcement learning, actor-critic algorithms generally use the recursive least squares (RLS) technology to update the parameter of linear function approximators for accelerating their convergence speed. However, A2C algorithms seldom use this technology to train deep neural networks (DNNs) for improving their sample efficiency. In this paper, we propose two novel RLS-based A2C algorithms and investigate their performance. Both proposed algorithms, called RLSSA2C and RLSNA2C, use the RLS method to train the critic network and the hidden layers of the actor network. The main difference between them is at the policy learning step. RLSSA2C uses an ordinary first-order gradient descent algorithm and the standard policy gradient to learn the policy parameter. RLSNA2C uses the Kronecker-factored approximation, the RLS method and the natural policy gradient to learn the compatible parameter and the policy parameter. In addition, we analyze the complexity and convergence of both algorithms, and present three tricks for further improving their convergence speed. Finally, we demonstrate the effectiveness of both algorithms on 40 games in the Atari 2600 environment and 11 tasks in the MuJoCo environment. From the experimental results, it is shown that our both algorithms have better sample efficiency than the vanilla A2C on most games or tasks, and have higher computational efficiency than other two state-of-the-art algorithms.