 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecurrent Distributed Reinforcement Learning for Partially Observable Robotic Assembly
Paper and Code
Oct 15, 2020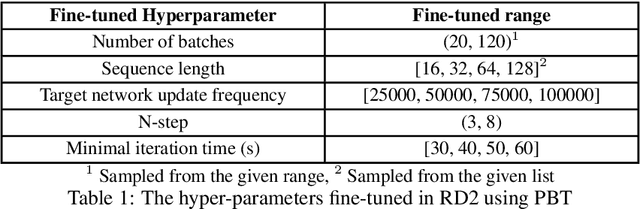
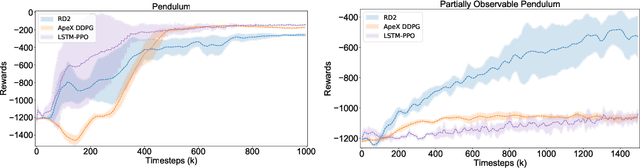
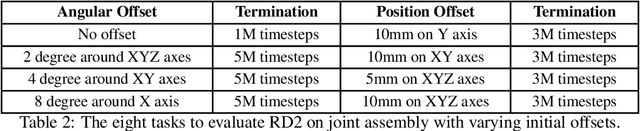
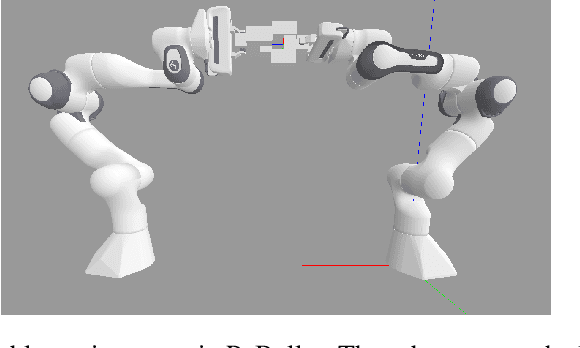
In this work we solve for partially observable reinforcement learning (RL) environments by adding recurrency. We focus on partially observable robotic assembly tasks in the continuous action domain, with force/torque sensing being the only observation. We have developed a new distributed RL agent, named Recurrent Distributed DDPG (RD2), which adds a recurrent neural network layer to Ape-X DDPG and makes two important improvements on prioritized experience replay to stabilize training. We demonstrate the effectiveness of RD2 on a variety of joint assembly tasks and a partially observable version of the pendulum task from OpenAI Gym. Our results show that RD2 is able to achieve better performance than Ape-X DDPG and PPO with LSTM on partially observable tasks with varying complexity. We also show that the trained models adapt well to different initial states and different types of noise injected in the simulated environment. The video presenting our experiments is available at https://sites.google.com/view/rd2-rl