Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecurrent Deep Stacking Networks for Speech Recognition
Paper and Code
Dec 14, 2016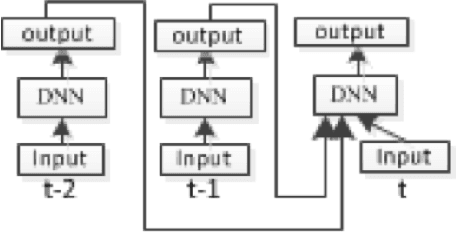
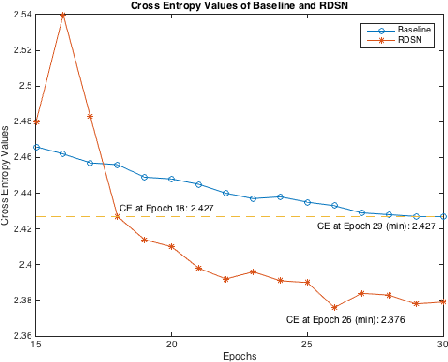
This paper presented our work on applying Recurrent Deep Stacking Networks (RDSNs) to Robust Automatic Speech Recognition (ASR) tasks. In the paper, we also proposed a more efficient yet comparable substitute to RDSN, Bi- Pass Stacking Network (BPSN). The main idea of these two models is to add phoneme-level information into acoustic models, transforming an acoustic model to the combination of an acoustic model and a phoneme-level N-gram model. Experiments showed that RDSN and BPsn can substantially improve the performances over conventional DNNs.
View paper on