 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecovering the number of clusters in data sets with noise features using feature rescaling factors
Paper and Code
Feb 22, 2016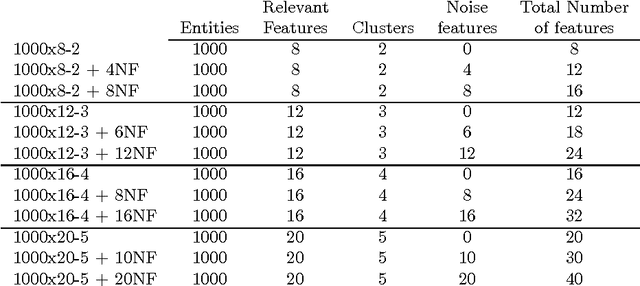

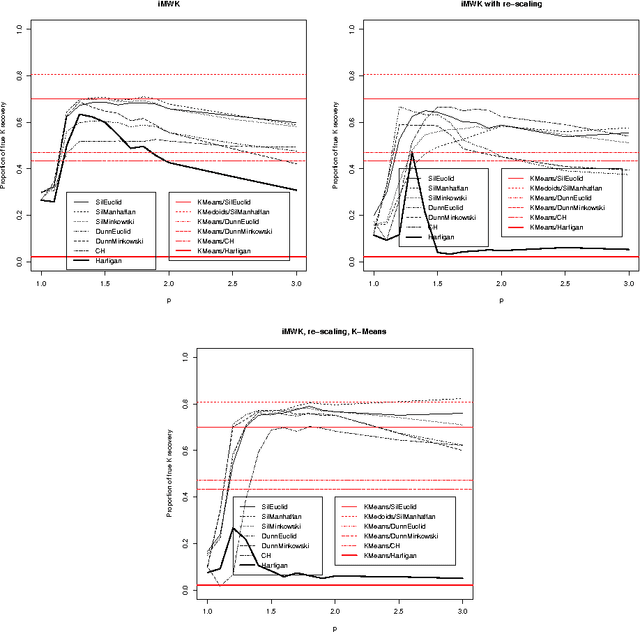
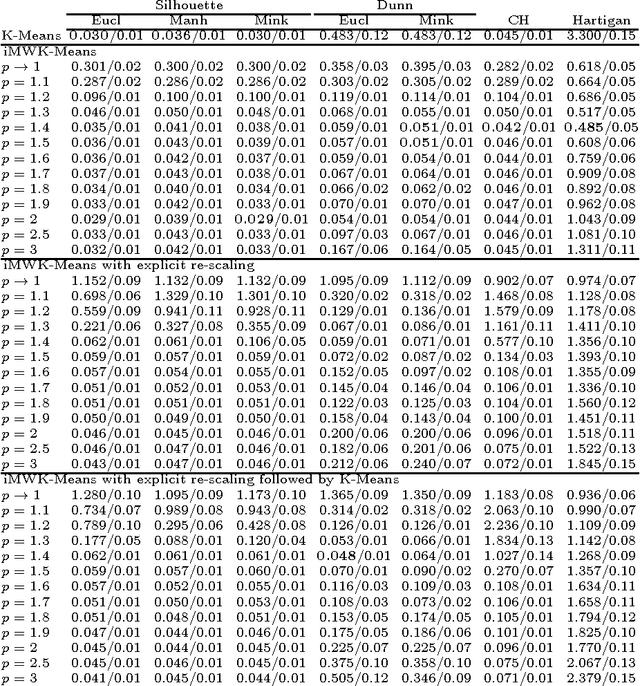
In this paper we introduce three methods for re-scaling data sets aiming at improving the likelihood of clustering validity indexes to return the true number of spherical Gaussian clusters with additional noise features. Our method obtains feature re-scaling factors taking into account the structure of a given data set and the intuitive idea that different features may have different degrees of relevance at different clusters. We experiment with the Silhouette (using squared Euclidean, Manhattan, and the p$^{th}$ power of the Minkowski distance), Dunn's, Calinski-Harabasz and Hartigan indexes on data sets with spherical Gaussian clusters with and without noise features. We conclude that our methods indeed increase the chances of estimating the true number of clusters in a data set.