 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReconstructing Sepsis Trajectories from Clinical Case Reports using LLMs: the Textual Time Series Corpus for Sepsis
Paper and Code
Apr 12, 2025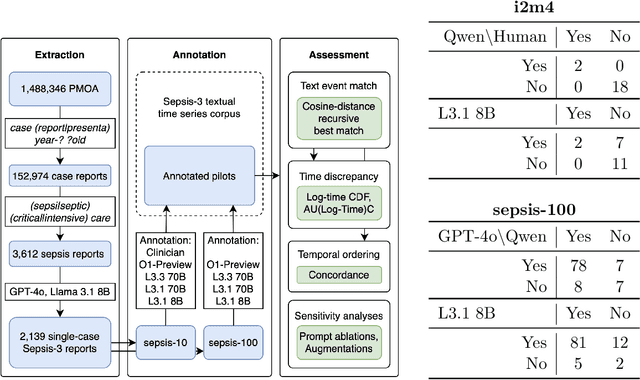
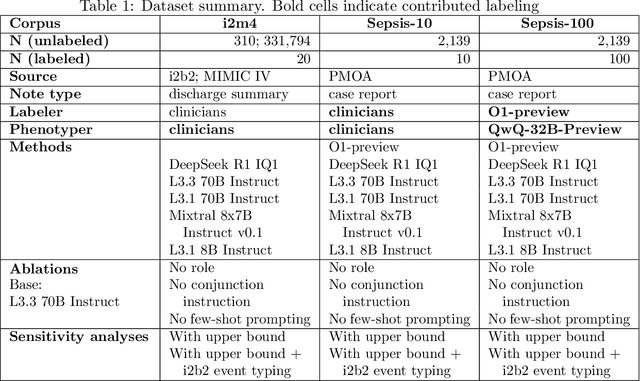
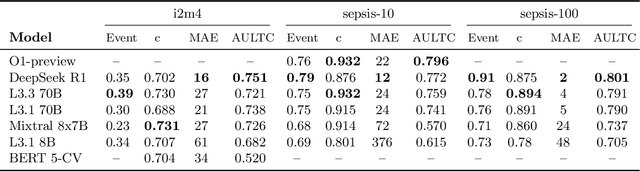
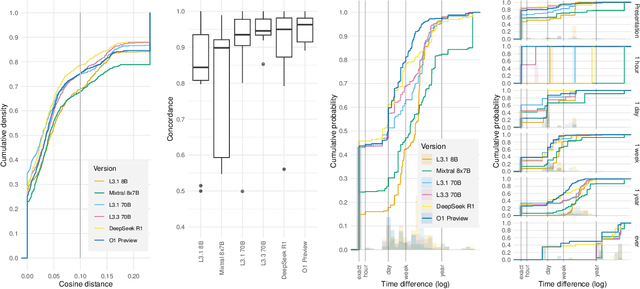
Clinical case reports and discharge summaries may be the most complete and accurate summarization of patient encounters, yet they are finalized, i.e., timestamped after the encounter. Complementary data structured streams become available sooner but suffer from incompleteness. To train models and algorithms on more complete and temporally fine-grained data, we construct a pipeline to phenotype, extract, and annotate time-localized findings within case reports using large language models. We apply our pipeline to generate an open-access textual time series corpus for Sepsis-3 comprising 2,139 case reports from the Pubmed-Open Access (PMOA) Subset. To validate our system, we apply it on PMOA and timeline annotations from I2B2/MIMIC-IV and compare the results to physician-expert annotations. We show high recovery rates of clinical findings (event match rates: O1-preview--0.755, Llama 3.3 70B Instruct--0.753) and strong temporal ordering (concordance: O1-preview--0.932, Llama 3.3 70B Instruct--0.932). Our work characterizes the ability of LLMs to time-localize clinical findings in text, illustrating the limitations of LLM use for temporal reconstruction and providing several potential avenues of improvement via multimodal integration.