 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReconstructing Kernel-based Machine Learning Force Fields with Super-linear Convergence
Paper and Code
Dec 24, 2022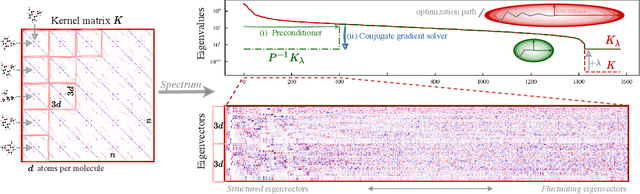
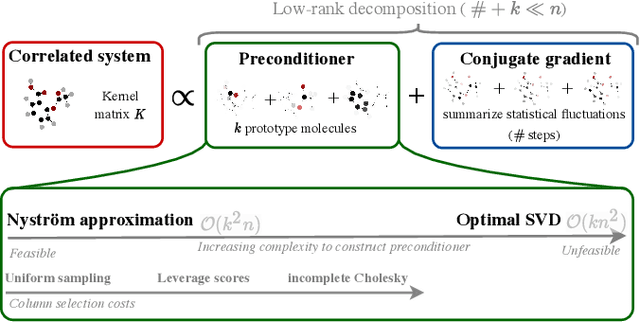

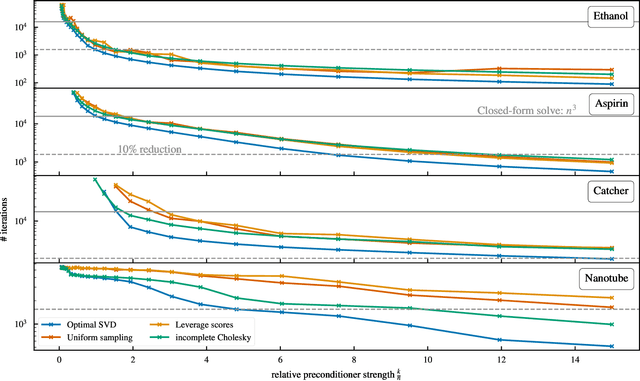
Kernel machines have sustained continuous progress in the field of quantum chemistry. In particular, they have proven to be successful in the low-data regime of force field reconstruction. This is because many physical invariances and symmetries can be incorporated into the kernel function to compensate for much larger datasets. So far, the scalability of this approach has however been hindered by its cubical runtime in the number of training points. While it is known, that iterative Krylov subspace solvers can overcome these burdens, they crucially rely on effective preconditioners, which are elusive in practice. Practical preconditioners need to be computationally efficient and numerically robust at the same time. Here, we consider the broad class of Nystr\"om-type methods to construct preconditioners based on successively more sophisticated low-rank approximations of the original kernel matrix, each of which provides a different set of computational trade-offs. All considered methods estimate the relevant subspace spanned by the kernel matrix columns using different strategies to identify a representative set of inducing points. Our comprehensive study covers the full spectrum of approaches, starting from naive random sampling to leverage score estimates and incomplete Cholesky factorizations, up to exact SVD decompositions.