 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReconciling modern machine learning and the bias-variance trade-off
Paper and Code
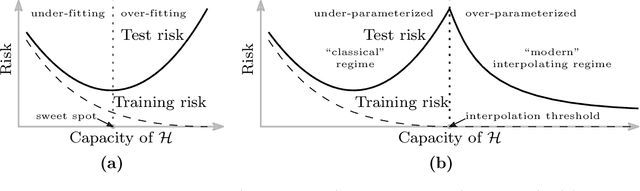
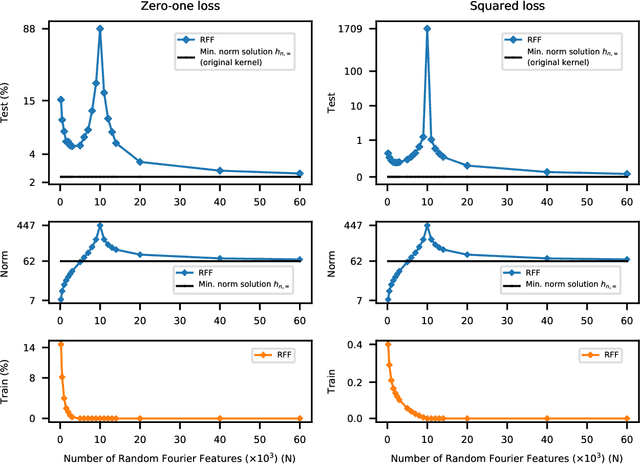
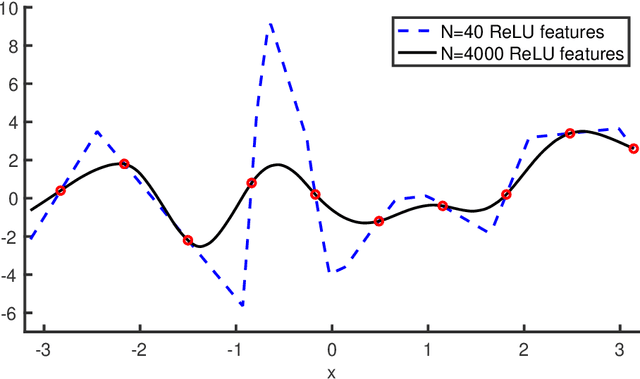
The question of generalization in machine learning---how algorithms are able to learn predictors from a training sample to make accurate predictions out-of-sample---is revisited in light of the recent breakthroughs in modern machine learning technology. The classical approach to understanding generalization is based on bias-variance trade-offs, where model complexity is carefully calibrated so that the fit on the training sample reflects performance out-of-sample. However, it is now common practice to fit highly complex models like deep neural networks to data with (nearly) zero training error, and yet these interpolating predictors are observed to have good out-of-sample accuracy even for noisy data. How can the classical understanding of generalization be reconciled with these observations from modern machine learning practice? In this paper, we bridge the two regimes by exhibiting a new "double descent" risk curve that extends the traditional U-shaped bias-variance curve beyond the point of interpolation. Specifically, the curve shows that as soon as the model complexity is high enough to achieve interpolation on the training sample---a point that we call the "interpolation threshold"---the risk of suitably chosen interpolating predictors from these models can, in fact, be decreasing as the model complexity increases, often below the risk achieved using non-interpolating models. The double descent risk curve is demonstrated for a broad range of models, including neural networks and random forests, and a mechanism for producing this behavior is posited.