 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReasonChainQA: Text-based Complex Question Answering with Explainable Evidence Chains
Paper and Code


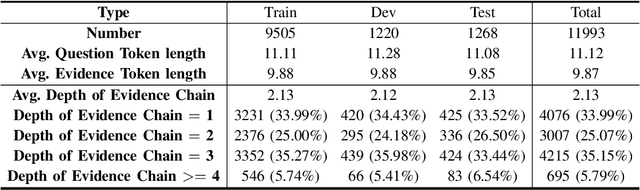

The ability of reasoning over evidence has received increasing attention in question answering (QA). Recently, natural language database (NLDB) conducts complex QA in knowledge base with textual evidences rather than structured representations, this task attracts a lot of attention because of the flexibility and richness of textual evidence. However, existing text-based complex question answering datasets fail to provide explicit reasoning process, while it's important for retrieval effectiveness and reasoning interpretability. Therefore, we present a benchmark \textbf{ReasonChainQA} with explanatory and explicit evidence chains. ReasonChainQA consists of two subtasks: answer generation and evidence chains extraction, it also contains higher diversity for multi-hop questions with varying depths, 12 reasoning types and 78 relations. To obtain high-quality textual evidences for answering complex question. Additional experiment on supervised and unsupervised retrieval fully indicates the significance of ReasonChainQA. Dataset and codes will be made publicly available upon accepted.