 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-World Super-Resolution of Face-Images from Surveillance Cameras
Paper and Code
Feb 05, 2021
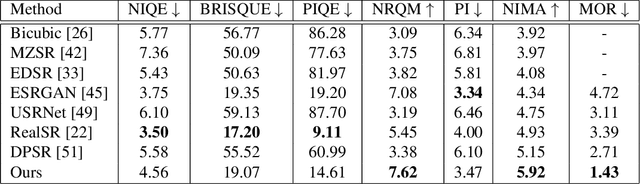


Most existing face image Super-Resolution (SR) methods assume that the Low-Resolution (LR) images were artificially downsampled from High-Resolution (HR) images with bicubic interpolation. This operation changes the natural image characteristics and reduces noise. Hence, SR methods trained on such data most often fail to produce good results when applied to real LR images. To solve this problem, we propose a novel framework for generation of realistic LR/HR training pairs. Our framework estimates realistic blur kernels, noise distributions, and JPEG compression artifacts to generate LR images with similar image characteristics as the ones in the source domain. This allows us to train a SR model using high quality face images as Ground-Truth (GT). For better perceptual quality we use a Generative Adversarial Network (GAN) based SR model where we have exchanged the commonly used VGG-loss [24] with LPIPS-loss [52]. Experimental results on both real and artificially corrupted face images show that our method results in more detailed reconstructions with less noise compared to existing State-of-the-Art (SoTA) methods. In addition, we show that the traditional non-reference Image Quality Assessment (IQA) methods fail to capture this improvement and demonstrate that the more recent NIMA metric [16] correlates better with human perception via Mean Opinion Rank (MOR).