 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRare geometries: revealing rare categories via dimension-driven statistics
Paper and Code
Jan 29, 2019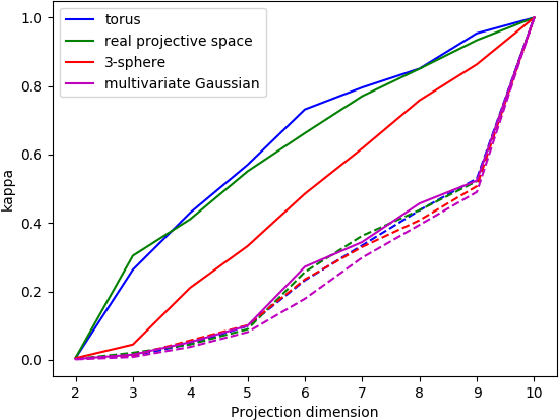
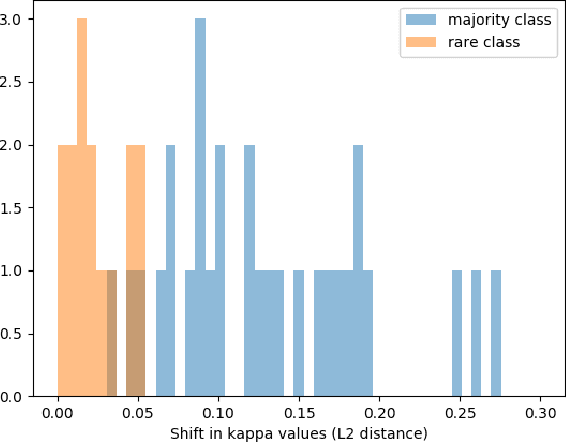
In many situations, the classes of data points of primary interest also happen to be those that are least numerous. A well-known example is detection of fraudulent transactions among the collection of all transactions, the majority of which are legitimate. These types of problems fall under the label of `rare category detection'. One challenging aspect of these problems is that a rare class may not be easily separable from the majority class (at least in terms of available features). Statistics related to the geometry of the rare class (such as its intrinsic dimension) can be significantly different from those for the majority class, reflecting the different dynamics driving variation in the different classes. In this paper we present a new supervised learning algorithm that uses a dimension-driven statistic, called the $\kappa$-profile, to classify unlabeled points as likely to belong to a rare class.