 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRanking with Features: Algorithm and A Graph Theoretic Analysis
Paper and Code
Aug 11, 2018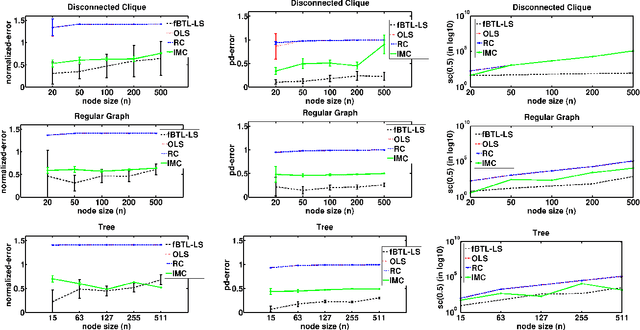
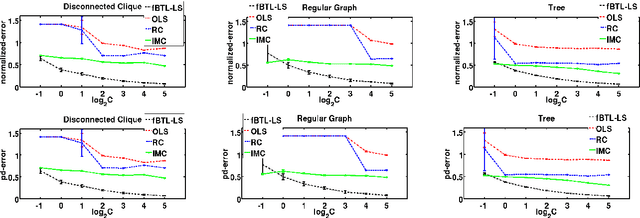
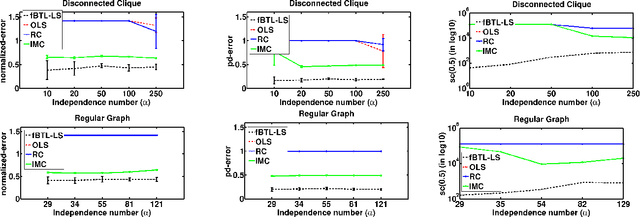

We consider the problem of ranking a set of items from pairwise comparisons in the presence of features associated with the items. Recent works have established that $O(n\log(n))$ samples are needed to rank well when there is no feature information present. However, this might be sub-optimal in the presence of associated features. We introduce a new probabilistic preference model called feature-Bradley-Terry-Luce (f-BTL) model that generalizes the standard BTL model to incorporate feature information. We present a new least squares based algorithm called fBTL-LS which we show requires much lesser than $O(n\log(n))$ pairs to obtain a good ranking -- precisely our new sample complexity bound is of $O(\alpha\log \alpha)$, where $\alpha$ denotes the number of `independent items' of the set, in general $\alpha << n$. Our analysis is novel and makes use of tools from classical graph matching theory to provide tighter bounds that sheds light on the true complexity of the ranking problem, capturing the item dependencies in terms of their feature representations. This was not possible with earlier matrix completion based tools used for this problem. We also prove an information theoretic lower bound on the required sample complexity for recovering the underlying ranking, which essentially shows the tightness of our proposed algorithms. The efficacy of our proposed algorithms are validated through extensive experimental evaluations on a variety of synthetic and real world datasets.