 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRandomized Stochastic Gradient Descent Ascent
Paper and Code
Nov 25, 2021
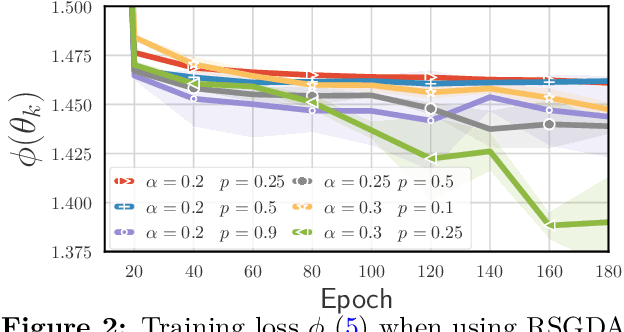
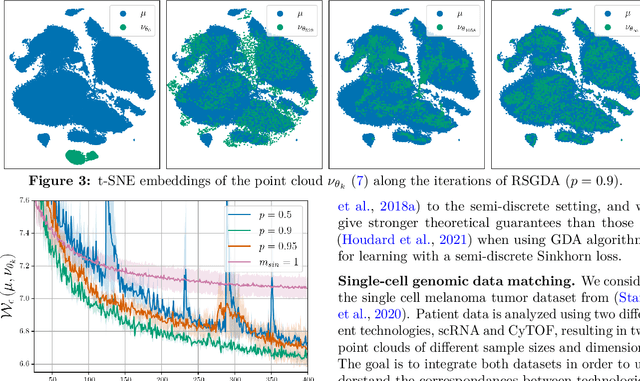
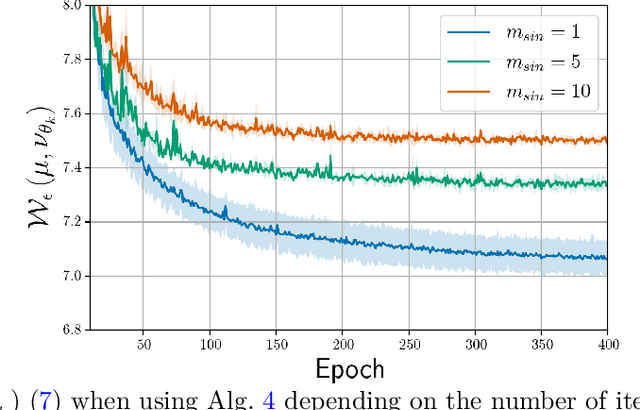
An increasing number of machine learning problems, such as robust or adversarial variants of existing algorithms, require minimizing a loss function that is itself defined as a maximum. Carrying a loop of stochastic gradient ascent (SGA) steps on the (inner) maximization problem, followed by an SGD step on the (outer) minimization, is known as Epoch Stochastic Gradient \textit{Descent Ascent} (ESGDA). While successful in practice, the theoretical analysis of ESGDA remains challenging, with no clear guidance on choices for the inner loop size nor on the interplay between inner/outer step sizes. We propose RSGDA (Randomized SGDA), a variant of ESGDA with stochastic loop size with a simpler theoretical analysis. RSGDA comes with the first (among SGDA algorithms) almost sure convergence rates when used on nonconvex min/strongly-concave max settings. RSGDA can be parameterized using optimal loop sizes that guarantee the best convergence rates known to hold for SGDA. We test RSGDA on toy and larger scale problems, using distributionally robust optimization and single-cell data matching using optimal transport as a testbed.