 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRandomization as Regularization: A Degrees of Freedom Explanation for Random Forest Success
Paper and Code


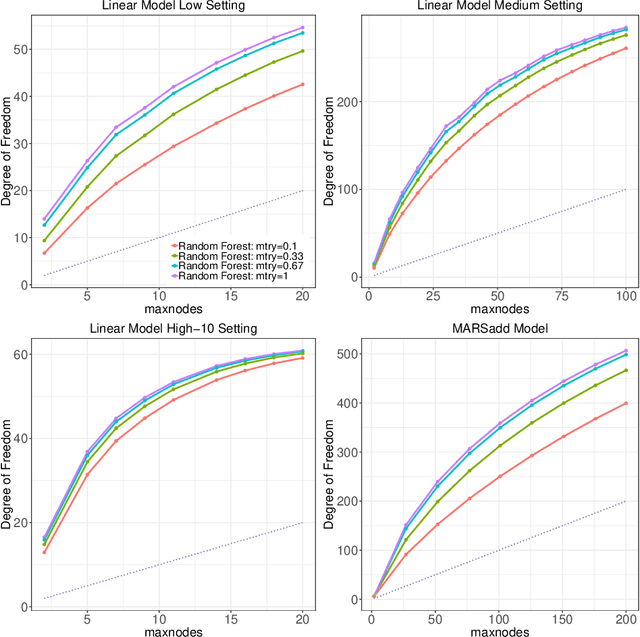
Random forests remain among the most popular off-the-shelf supervised machine learning tools with a well-established track record of predictive accuracy in both regression and classification settings. Despite their empirical success as well as a bevy of recent work investigating their statistical properties, a full and satisfying explanation for their success has yet to be put forth. Here we aim to take a step forward in this direction by demonstrating that the additional randomness injected into individual trees serves as a form of implicit regularization, making random forests an ideal model in low signal-to-noise ratio (SNR) settings. Specifically, from a model-complexity perspective, we show that the mtry parameter in random forests serves much the same purpose as the shrinkage penalty in explicitly regularized regression procedures like lasso and ridge regression. To highlight this point, we design a randomized linear-model-based forward selection procedure intended as an analogue to tree-based random forests and demonstrate its surprisingly strong empirical performance. Numerous demonstrations on both real and synthetic data are provided.