 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRandom Reshuffling with Variance Reduction: New Analysis and Better Rates
Paper and Code


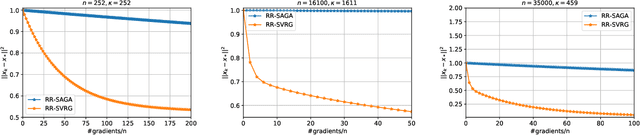

Virtually all state-of-the-art methods for training supervised machine learning models are variants of SGD enhanced with a number of additional tricks, such as minibatching, momentum, and adaptive stepsizes. One of the tricks that works so well in practice that it is used as default in virtually all widely used machine learning software is {\em random reshuffling (RR)}. However, the practical benefits of RR have until very recently been eluding attempts at being satisfactorily explained using theory. Motivated by recent development due to Mishchenko, Khaled and Richt\'{a}rik (2020), in this work we provide the first analysis of SVRG under Random Reshuffling (RR-SVRG) for general finite-sum problems. First, we show that RR-SVRG converges linearly with the rate $\mathcal{O}(\kappa^{3/2})$ in the strongly-convex case, and can be improved further to $\mathcal{O}(\kappa)$ in the big data regime (when $n > \mathcal{O}(\kappa)$), where $\kappa$ is the condition number. This improves upon the previous best rate $\mathcal{O}(\kappa^2)$ known for a variance reduced RR method in the strongly-convex case due to Ying, Yuan and Sayed (2020). Second, we obtain the first sublinear rate for general convex problems. Third, we establish similar fast rates for Cyclic-SVRG and Shuffle-Once-SVRG. Finally, we develop and analyze a more general variance reduction scheme for RR, which allows for less frequent updates of the control variate. We corroborate our theoretical results with suitably chosen experiments on synthetic and real datasets.