 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRandom matrices in service of ML footprint: ternary random features with no performance loss
Paper and Code
Oct 05, 2021


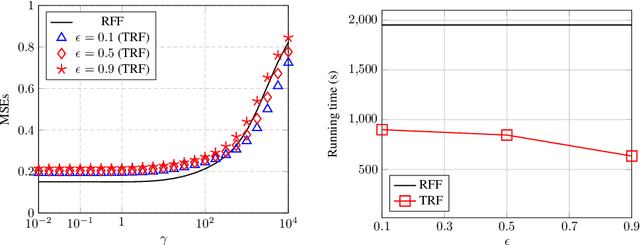
In this article, we investigate the spectral behavior of random features kernel matrices of the type ${\bf K} = \mathbb{E}_{{\bf w}} \left[\sigma\left({\bf w}^{\sf T}{\bf x}_i\right)\sigma\left({\bf w}^{\sf T}{\bf x}_j\right)\right]_{i,j=1}^n$, with nonlinear function $\sigma(\cdot)$, data ${\bf x}_1, \ldots, {\bf x}_n \in \mathbb{R}^p$, and random projection vector ${\bf w} \in \mathbb{R}^p$ having i.i.d. entries. In a high-dimensional setting where the number of data $n$ and their dimension $p$ are both large and comparable, we show, under a Gaussian mixture model for the data, that the eigenspectrum of ${\bf K}$ is independent of the distribution of the i.i.d.(zero-mean and unit-variance) entries of ${\bf w}$, and only depends on $\sigma(\cdot)$ via its (generalized) Gaussian moments $\mathbb{E}_{z\sim \mathcal N(0,1)}[\sigma'(z)]$ and $\mathbb{E}_{z\sim \mathcal N(0,1)}[\sigma''(z)]$. As a result, for any kernel matrix ${\bf K}$ of the form above, we propose a novel random features technique, called Ternary Random Feature (TRF), that (i) asymptotically yields the same limiting kernel as the original ${\bf K}$ in a spectral sense and (ii) can be computed and stored much more efficiently, by wisely tuning (in a data-dependent manner) the function $\sigma$ and the random vector ${\bf w}$, both taking values in $\{-1,0,1\}$. The computation of the proposed random features requires no multiplication, and a factor of $b$ times less bits for storage compared to classical random features such as random Fourier features, with $b$ the number of bits to store full precision values. Besides, it appears in our experiments on real data that the substantial gains in computation and storage are accompanied with somewhat improved performances compared to state-of-the-art random features compression/quantization methods.