 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRandom forest models of the retention constants in the thin layer chromatography
Paper and Code
Jun 16, 2011

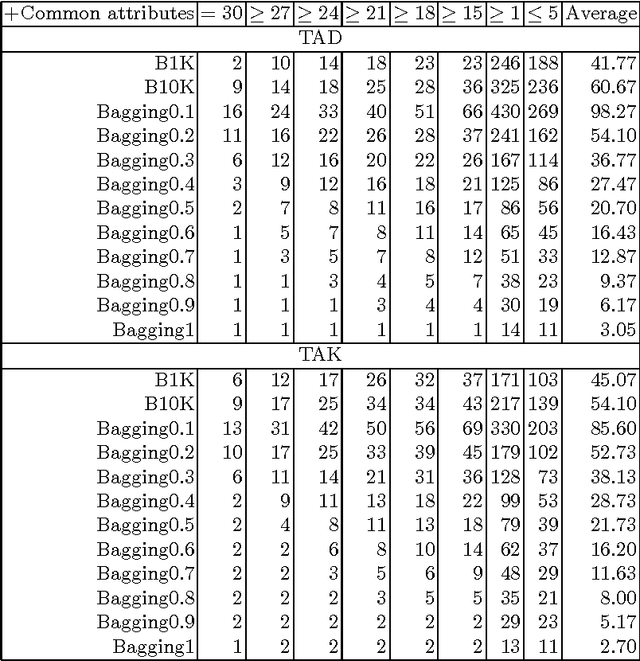
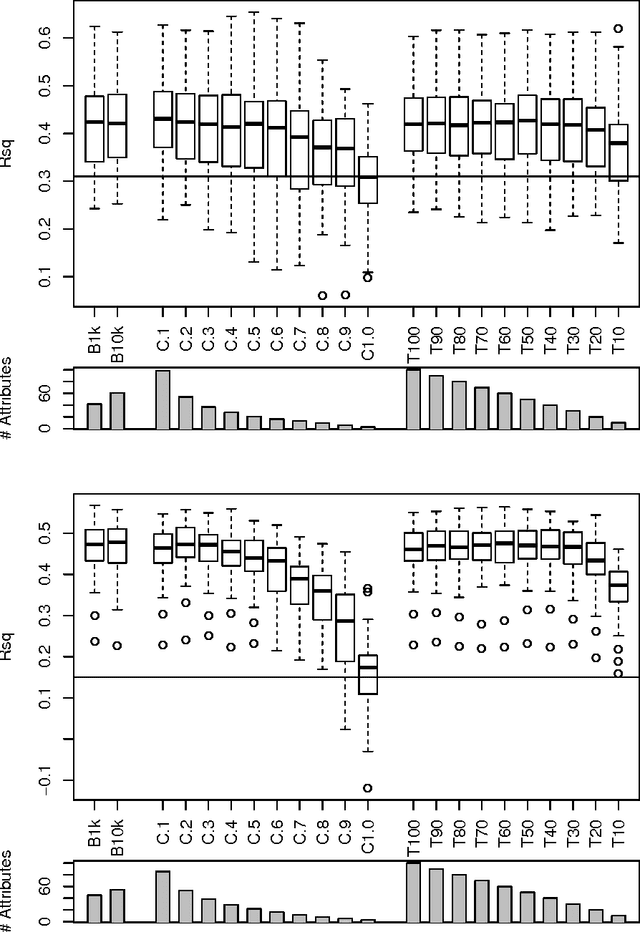
In the current study we examine an application of the machine learning methods to model the retention constants in the thin layer chromatography (TLC). This problem can be described with hundreds or even thousands of descriptors relevant to various molecular properties, most of them redundant and not relevant for the retention constant prediction. Hence we employed feature selection to significantly reduce the number of attributes. Additionally we have tested application of the bagging procedure to the feature selection. The random forest regression models were built using selected variables. The resulting models have better correlation with the experimental data than the reference models obtained with linear regression. The cross-validation confirms robustness of the models.