 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRandom Directional Attack for Fooling Deep Neural Networks
Paper and Code


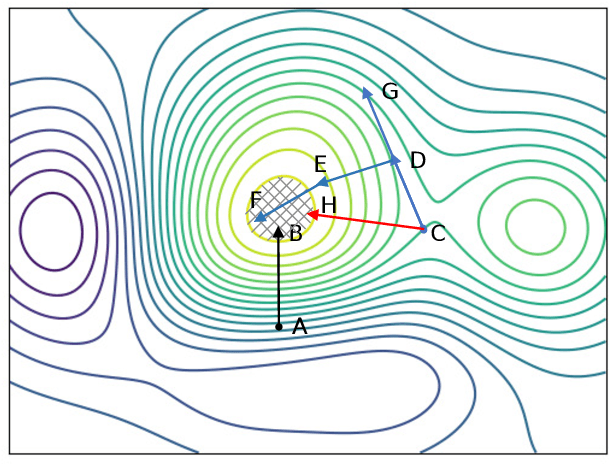
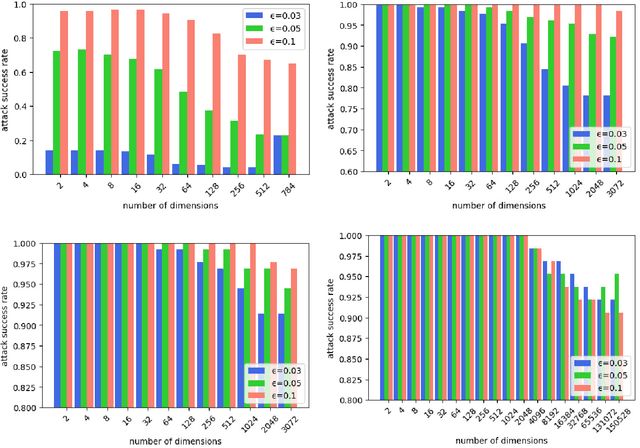
Deep neural networks (DNNs) have been widely used in many fields such as images processing, speech recognition; however, they are vulnerable to adversarial examples, and this is a security issue worthy of attention. Because the training process of DNNs converge the loss by updating the weights along the gradient descent direction, many gradient-based methods attempt to destroy the DNN model by adding perturbations in the gradient direction. Unfortunately, as the model is nonlinear in most cases, the addition of perturbations in the gradient direction does not necessarily increase loss. Thus, we propose a random directed attack (RDA) for generating adversarial examples in this paper. Rather than limiting the gradient direction to generate an attack, RDA searches the attack direction based on hill climbing and uses multiple strategies to avoid local optima that cause attack failure. Compared with state-of-the-art gradient-based methods, the attack performance of RDA is very competitive. Moreover, RDA can attack without any internal knowledge of the model, and its performance under black-box attack is similar to that of the white-box attack in most cases, which is difficult to achieve using existing gradient-based attack methods.