 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRaFoLa: A Rationale-Annotated Corpus for Detecting Indicators of Forced Labour
Paper and Code
May 05, 2022
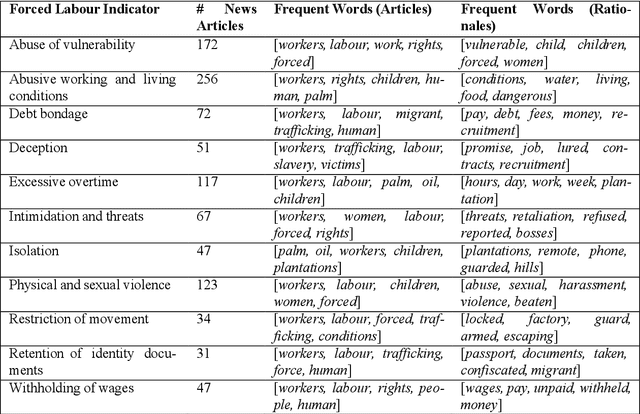
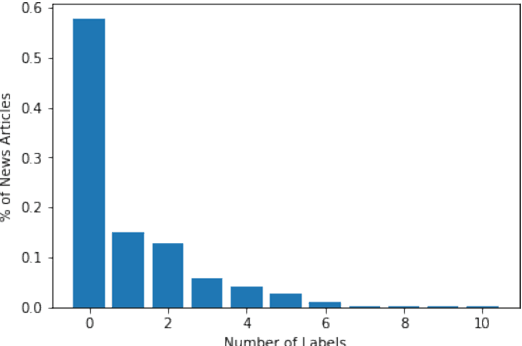
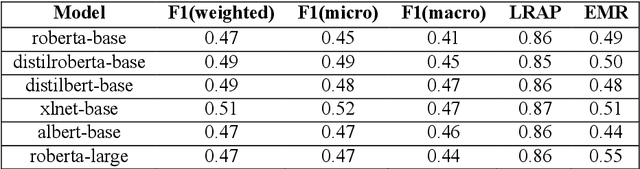
Forced labour is the most common type of modern slavery, and it is increasingly gaining the attention of the research and social community. Recent studies suggest that artificial intelligence (AI) holds immense potential for augmenting anti-slavery action. However, AI tools need to be developed transparently in cooperation with different stakeholders. Such tools are contingent on the availability and access to domain-specific data, which are scarce due to the near-invisible nature of forced labour. To the best of our knowledge, this paper presents the first openly accessible English corpus annotated for multi-class and multi-label forced labour detection. The corpus consists of 989 news articles retrieved from specialised data sources and annotated according to risk indicators defined by the International Labour Organization (ILO). Each news article was annotated for two aspects: (1) indicators of forced labour as classification labels and (2) snippets of the text that justify labelling decisions. We hope that our data set can help promote research on explainability for multi-class and multi-label text classification. In this work, we explain our process for collecting the data underpinning the proposed corpus, describe our annotation guidelines and present some statistical analysis of its content. Finally, we summarise the results of baseline experiments based on different variants of the Bidirectional Encoder Representation from Transformer (BERT) model.