 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQueue-based Resampling for Online Class Imbalance Learning
Paper and Code
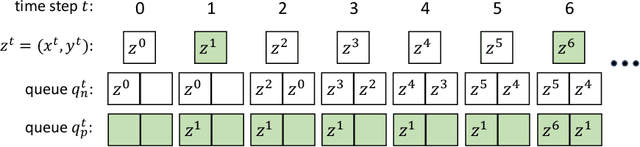
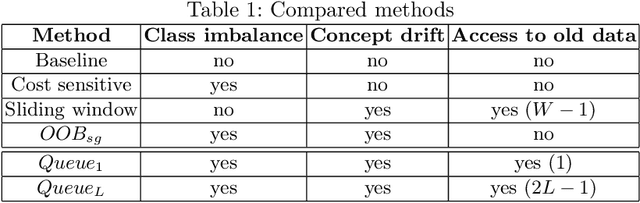


Online class imbalance learning constitutes a new problem and an emerging research topic that focusses on the challenges of online learning under class imbalance and concept drift. Class imbalance deals with data streams that have very skewed distributions while concept drift deals with changes in the class imbalance status. Little work exists that addresses these challenges and in this paper we introduce queue-based resampling, a novel algorithm that successfully addresses the co-existence of class imbalance and concept drift. The central idea of the proposed resampling algorithm is to selectively include in the training set a subset of the examples that appeared in the past. Results on two popular benchmark datasets demonstrate the effectiveness of queue-based resampling over state-of-the-art methods in terms of learning speed and quality.